HiveSQL实战积累_窗口函数
1.窗口函数基本概念
1.1 窗口函数概述
窗口函数能够使用一行或多行的值来返回每一行的值,出现在select子句的表达式列表中。over是关键字,用来指定函数执行的窗口范围,over关键字中包含三个分析子句:分组(partition by)、排序(order by)和Frame窗口区间。
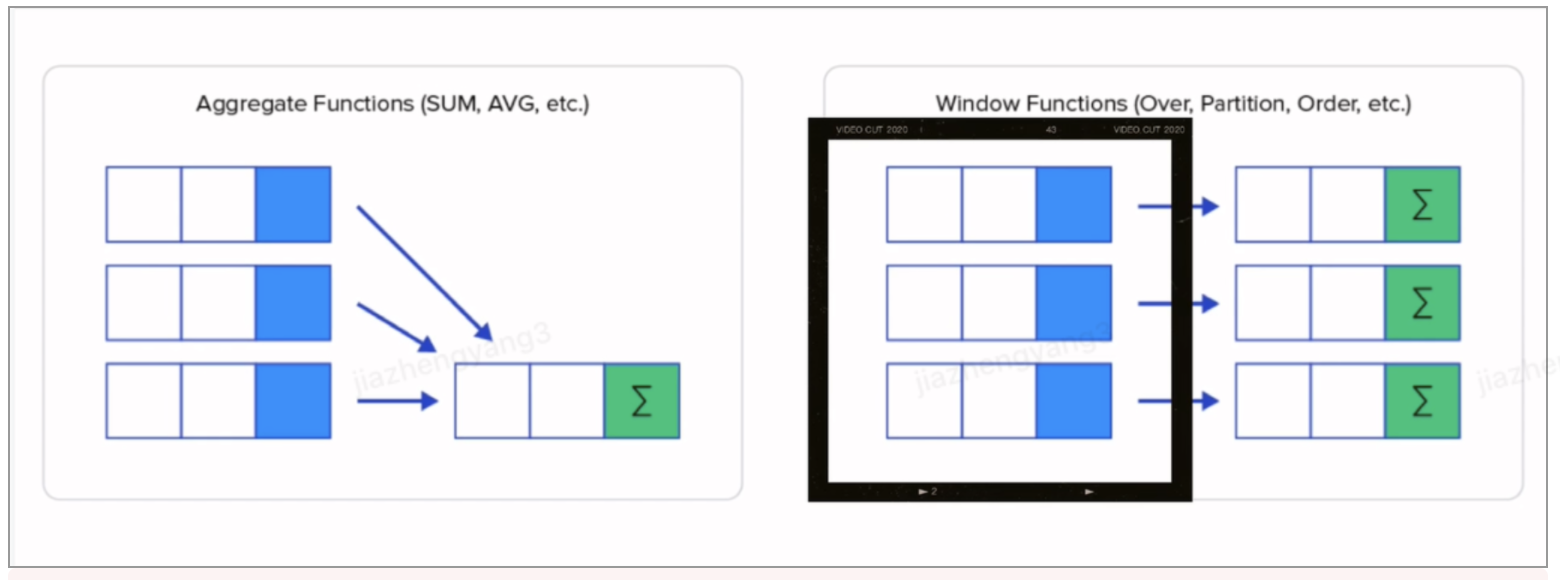
如上图所示,将窗口函数与group by进行比较:group by就是使用聚合函数是将多条记录聚合为1条,窗口函数则是使用函数对圈定窗口中的数据进行计算然后得到计算值返回给每一行,不会改变原本的行数。
窗口函数表达式如下:
1 | SELECT |
窗口函数支持的函数类型:
- 聚合函数:sum(…)、 count(…)、max(…)、min(…)、avg(…)
- 排序函数:rank( )、dense_rank( )、row_number( )
- 偏移分析函数:lead(…)、lag(…)、 first_value(…)、last_value(…)
over关键字:
- partition by:分组的字段
- order by:排序的字段(默认升序ASC)
- Frame:窗口区间,用于指定计算数据的窗口边界,支持rows、range两种模式
1.2 Frame窗口区间原理
按partition by分组字段相同的key得到的所有数据行即为窗口函数的窗口,可以进一步使用Frame窗口区间来对这个窗口中的数据进行划界,指定函数作用的数据范围。
窗口示意图如下:
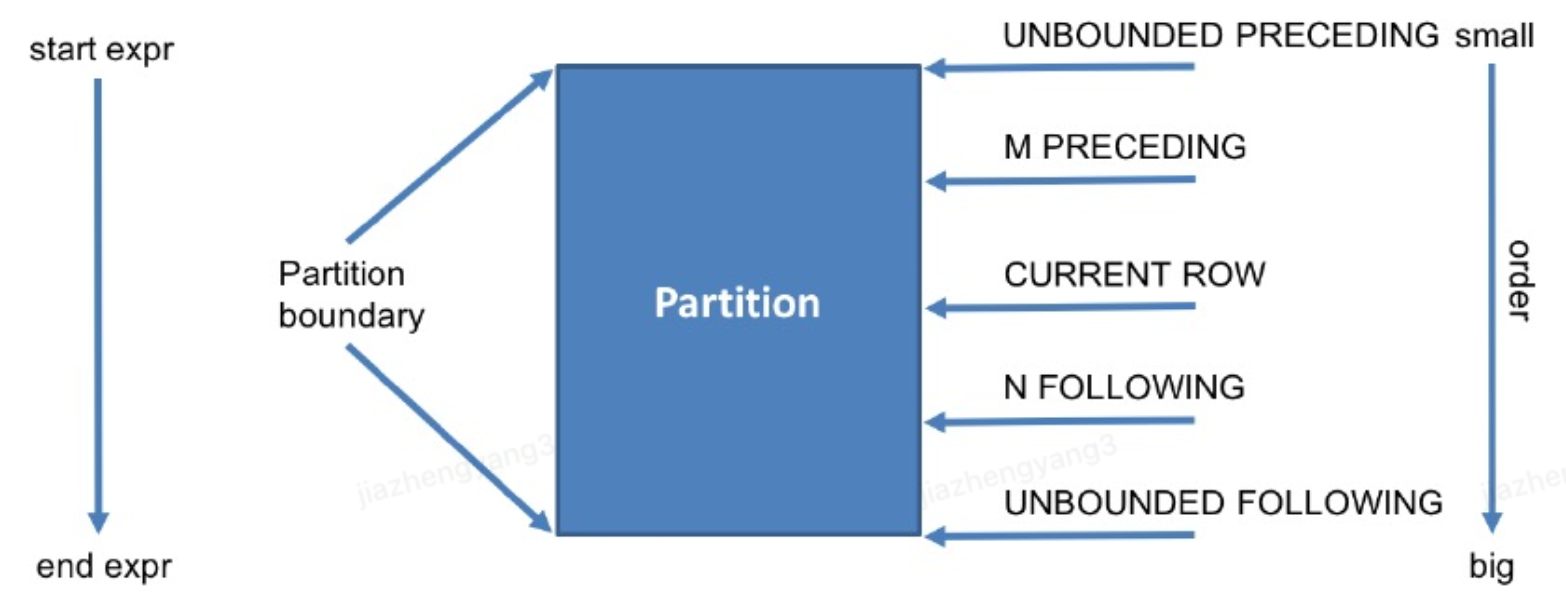
其中各名词的含义如下:
1 | preceding 往前 |
Frame窗口区间的两种写法是rows/range between <数据范围>,如下:
1 | rows/range between unbounded preceding and unbounded following --取窗口中的所有行,这是不加order by排序字段时的默认计算范围 |
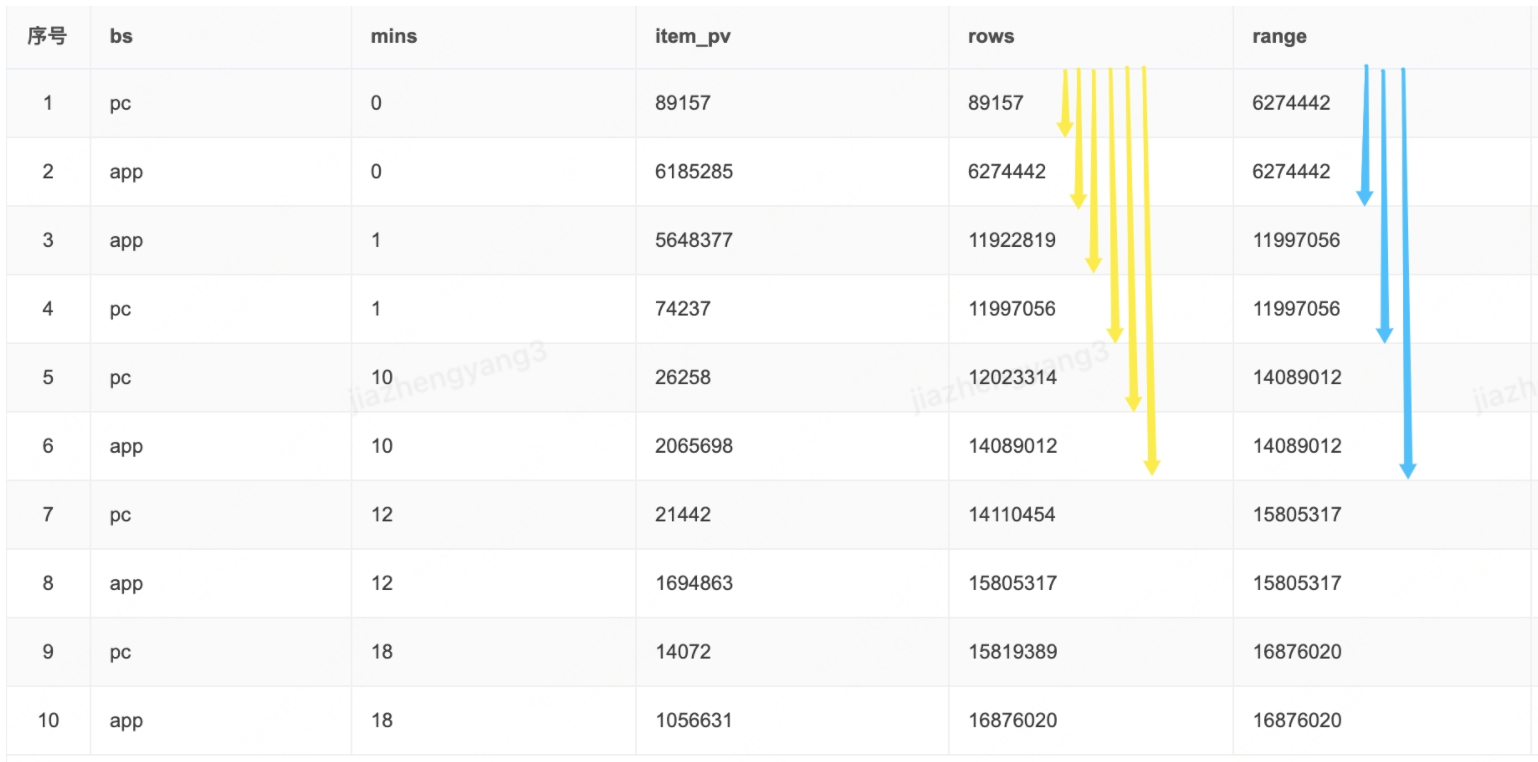
rows/range两种模式的区别:rows模式按物理行来进行划分,判断依据是行数;range模式按数值逻辑来进行行划分,要使用range模式的前提是有order by排序字段。如果例子很容易就可以看出区别:
1 | SELECT |
2.窗口函数分类
2.1 聚合函数
- count(*):计算目标表中的所有行,包括null值。
- count(col):计算特定列或表达式中非null值的行数。
- sum(col):返回值的表达式总和,忽略null值。
- max(col)/min(col):返回输入表达式值中的最大/小值,忽略null值。
- avg(col):返回输入表达式值的平均值,忽略null值。
应用实例sql如下:
1 | select |
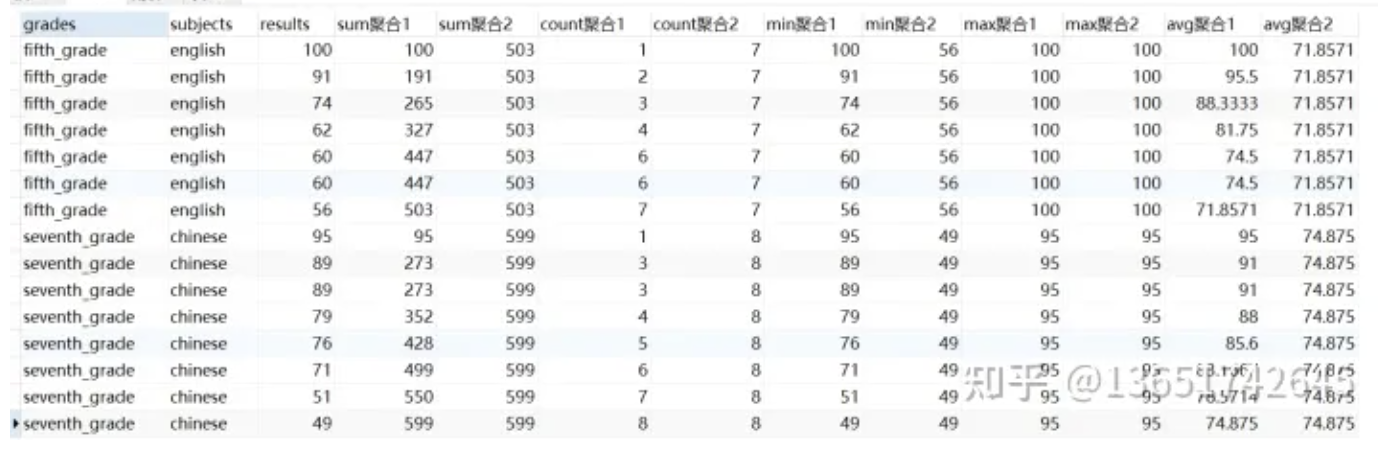
其中聚合1表示将数据集按照grades、subjects进行分组后,按照results降序排序,将每组中的results依次聚合;聚合2表示将数据集按照grades、subjects进行分组后,将每组中的results整体聚合。其中聚合1与聚合2的差异来源于order by排序字段的默认Frame窗口区间,有order by的默认窗口区间是rows between unbounded preceding and current row,没有order by的默认窗口区间是rows between unbounded preceding and unbounded following。也可以在聚合1的over关键字最后加上窗口区间rows between unbounded preceding and unbounded following,使得聚合1与聚合2的计算结果相同。
2.2 排序函数
- rank( ):bigint类型,形如1,2,2,4…(序号可以重复,序号不连续),排名,占用下一名次的位置。
- dense_rank( ):bigint类型,形如:1,2,2,3…(序号可以重复,序号连续),排名,不占用下一名次的位置。
- row_number( ):bigint类型,形如:1,2,3,4…(序号不重复,序号连续),编号。
- cume_dist():double类型,分组内小于等于当前rank的行值/分组内的总行数(查询<=当前计算值的比例),重复值取重复值最后一行位置(0,1]。
- percent_rank():double类型,返回数据集中每个数据的排名百分比,可以用来计算超过了百分之多少的人,排名计算公式为:(当前行的rank值-1)/(分组内的总行数-1),重复值取重复值第一行位置[0,1]。
- ntile(n):bigint类型,将每个窗口分区的数据分散到桶号从1到n的n个桶中。
应用实例sql如下:
1 | select |
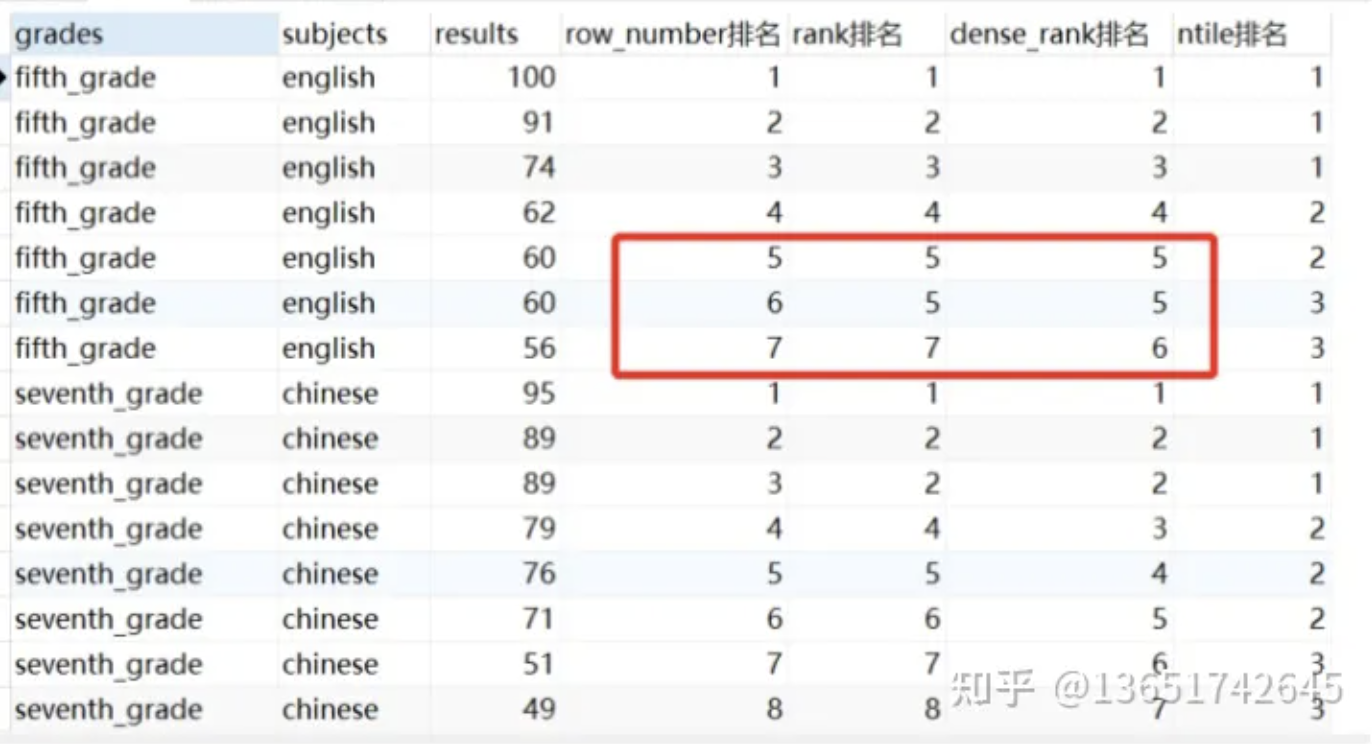
2.3 偏移分析函数
- lead(col,n,m):返回当前行的后n行,lead(要取的列, 往下取n行(可选,默认为1),如果没有下一行默认null)。
- lag(col,n,m):返回当前行的前n行,lead(要取的列, 往上取n行(可选,默认为1),如果没有上一行默认null)。
- first_value():取分组内排序后,截止到当前行的第一个值,默认窗口区间为rows between unbounded preceding and current row。
- last_value():取分组内排序后,截止到当前行的最后一个值,默认窗口区间为rows between unbounded preceding and current row。
应用实例sql如下:
1 | select |
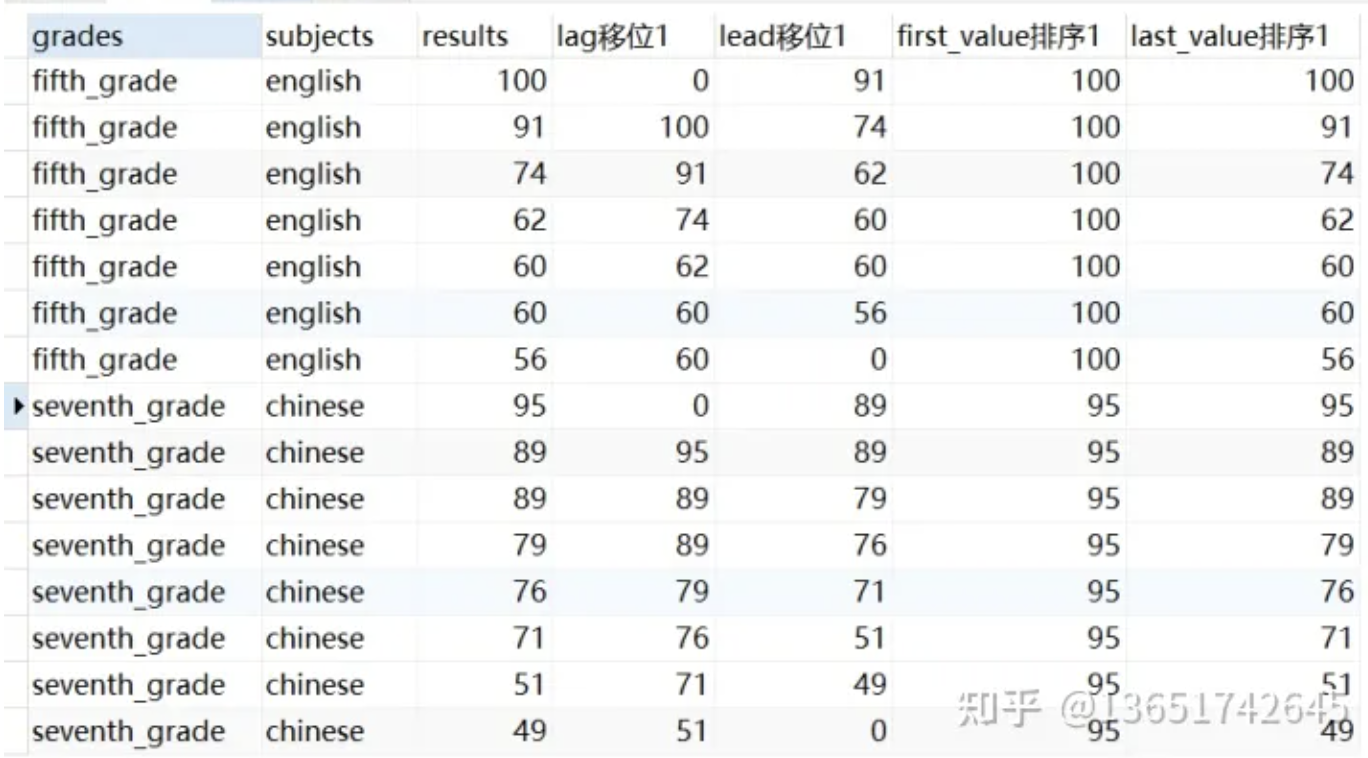
加order by排序字段代表将数据集按照grades、subjects进行分组后,再根据results降序排序,然后以默认窗口区间rows between unbounded preceding and current row进行运算。若不加order by则是对分组后的数据直接运算,也就是默认窗口区间rows between unbounded preceding and unbounded following。
3.partitionBy&distributeBy区别
3.1 order by全局排序
order by会对数据进行一次全局排序,只要hivesql中指定了order by,那么最后所有的数据都会到同一个reducer进行排序处理,所以数据量特别大的时候效率非常低。
3.2 sort by局部排序
sort by在每个reducer端都会做排序,为每个reduce产生一个排序文件,也就是说sort by能保证局部有序,就是每个reducer出来的数据是有序的,但是不能保证所有的数据是有序的,除非只有一个reducer。使用sort by的好处是,执行了局部排序之后可以为接下去的全局排序提高不少的效率。
3.3 distribute by分区
distribute by是控制map的输出在reducer是如何划分的,可以控制某个特定数据行应该到哪个reducer。默认情况下采集hash算法,将map端输出数据中hash值相同的结果分发到同一个reducer上。
distribute by经常和sort by配合使用。
3.4 group by
group by和distribute by类似 都是按key值划分数据到不同reduce进行处理。唯一不同的是,distribute by只是单纯的分散数据;而group by是为了把相同key的数据聚集到一起,后续必须是聚合操作。
3.5 cluster by
cluster by 除了distribute by 的功能外,还会对该字段进行排序。所以distribute by和 sort by合用且by相同字段就相当于cluster by,但是cluster by不能指定排序为asc或 desc的规则,只能是升序排列。
3.6 distribute by与partition by的区别
partition by不能用在where后面,partition by只能与order by配合在窗口函数中使用,而distribute by在窗口函数和where后面都可以使用。在窗口函数中partition by [key..] order by [key..]和distribute by [key…] sort by [key…]两者没有任何区别。
4.分时累积预计算实战
4.1 数据加工路径
实时离线对比页面或者单日趋势图页面经常需要用到分时累计数据,此处以单日10分钟累计流量指标pv、uv预计算为例,展示窗口函数在分时累计预计算中的使用,加工路径如下图所示:
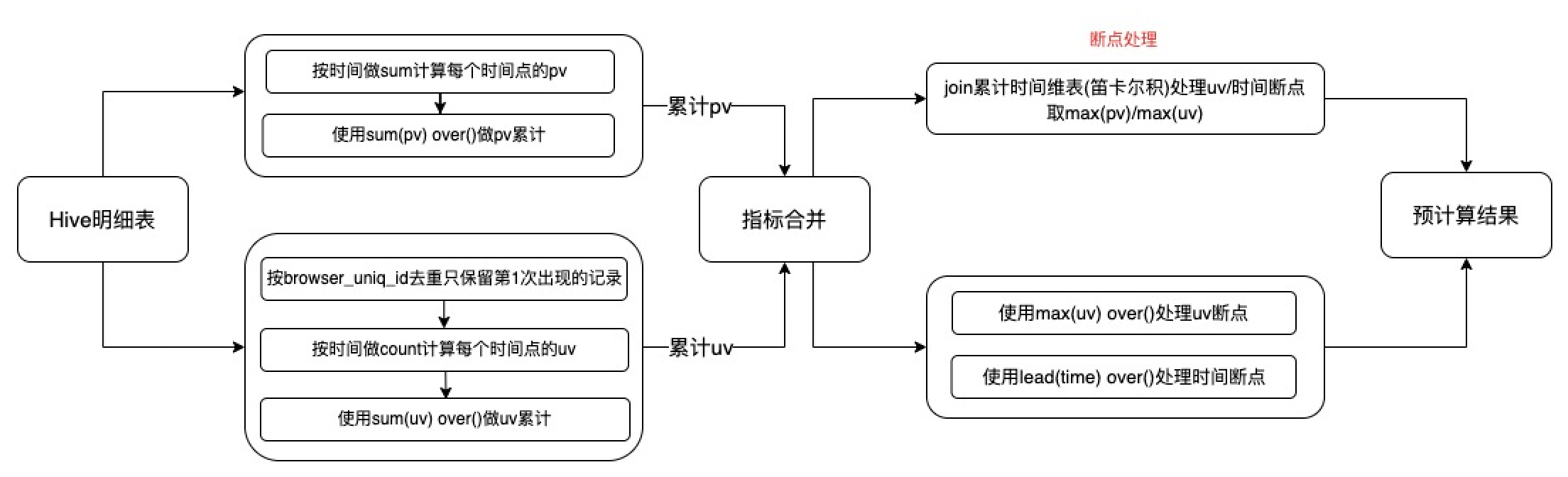
图中的时间断点是指,某些时间区间内没有pv或uv,导致采用窗口函数累加得到的数据表中,没有该时间维度行;uv断点是指某些时间区间内有pv但是没有uv,导致累加完之后的两指标合并之后,该时间维度行的uv为0或空。
4.2 指标分时统计再窗口函数累加
sql实例:
1 | SELECT |
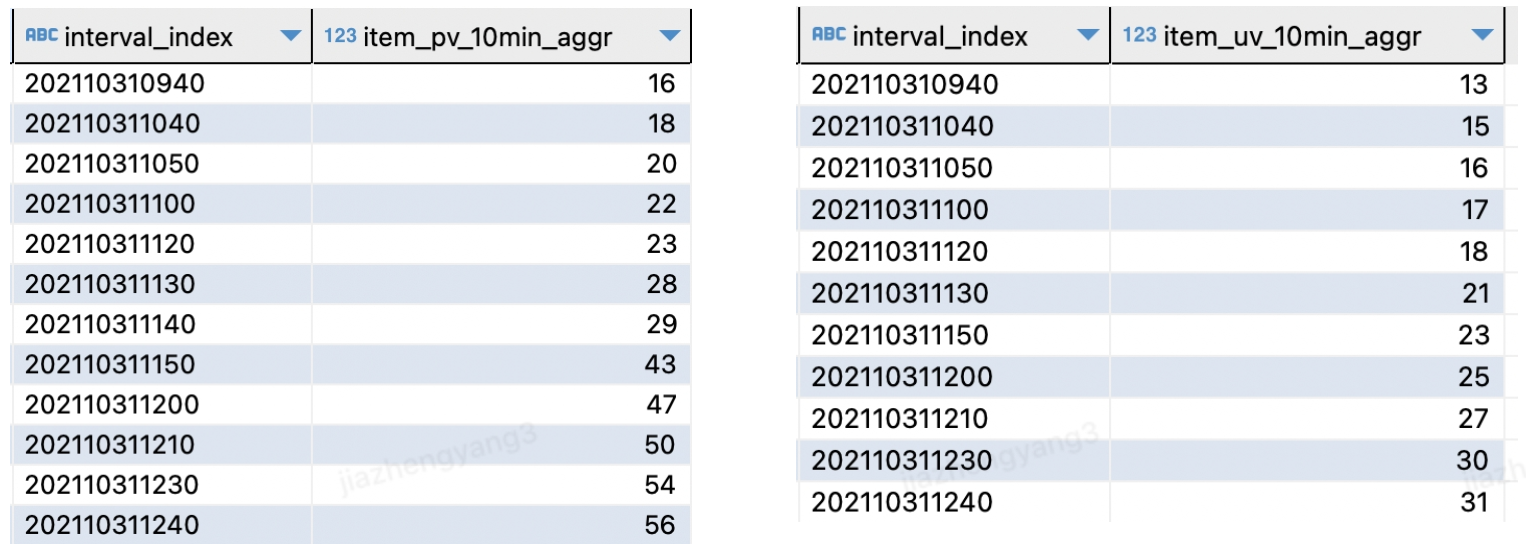
分别使用窗口函数累加得到的pv和uv如上图所示,明显可以看出存在时间断点,且pv数据条数比uv数据条数要多,将两个指标合并之后,可以看出存在uv断点,如下图所示。
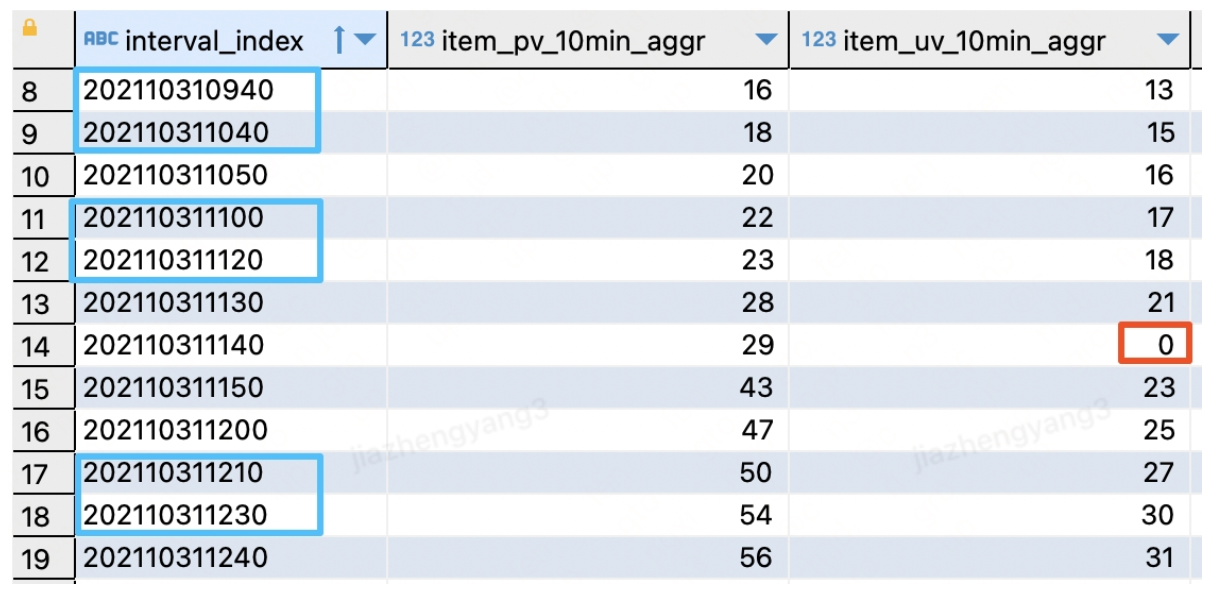
4.3 join时间维表补全断点
sql实例:
1 | SELECT |
此处通过join时间维表得到笛卡尔积将数据爆炸开来,其中时间维表存储的数据格式类似如下表:
| g_mins | d_mins |
|---|---|
| 0 | 0 |
| 1 | 0 |
| 1 | 1 |
| 2 | 0 |
| 2 | 1 |
| 2 | 2 |
| 3 | 0 |
| 3 | 1 |
| 3 | 2 |
| 3 | 3 |
运行sql补全时间和uv断点,得到计算结果如下图所示:
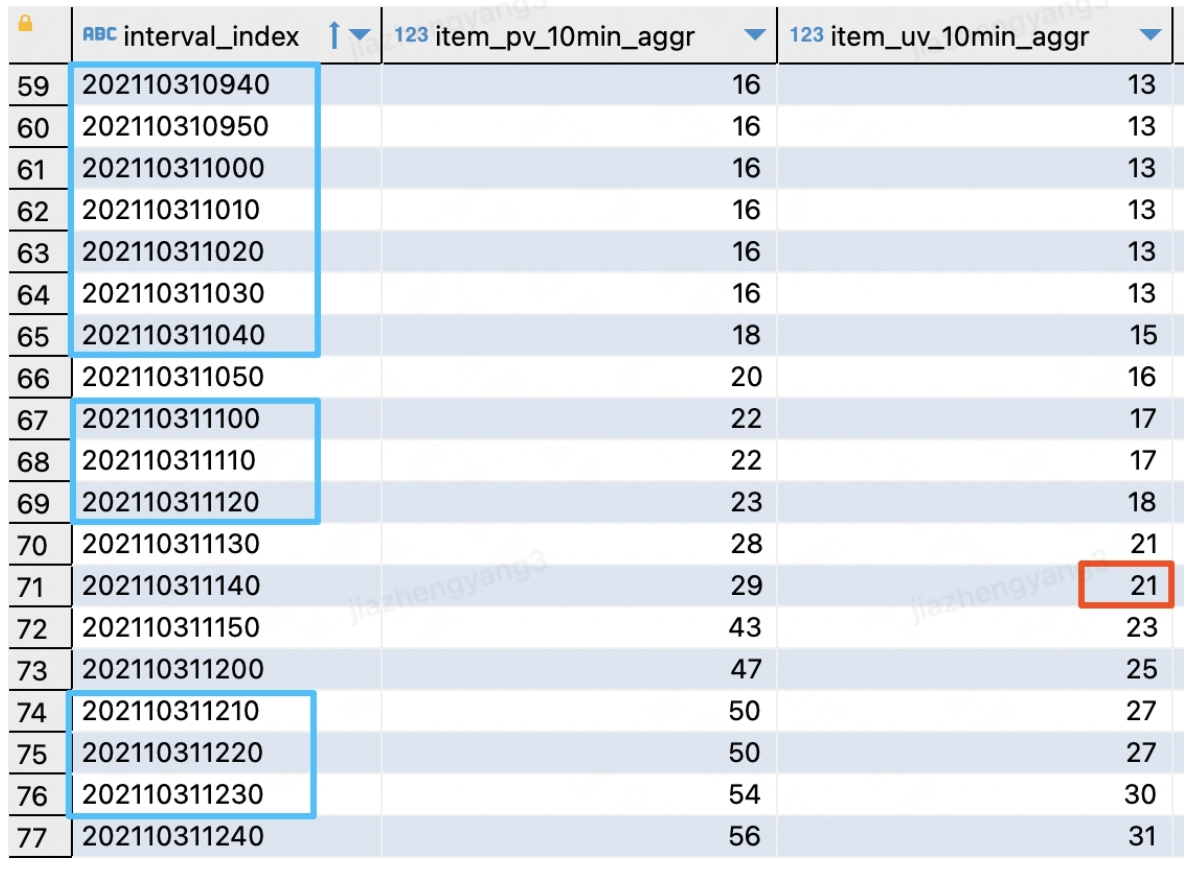
5.串行窗口函数优化实战
5.1 单个select中多个窗口函数执行顺序
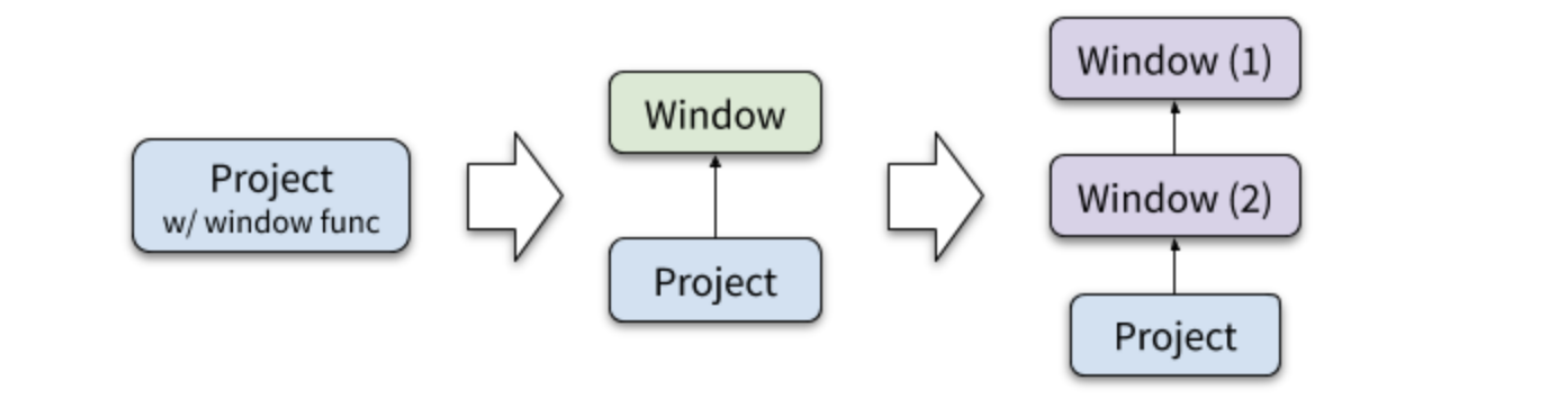
对于窗口函数,优化器能做的优化有限,首先会把窗口函数从project中抽取出来,成为一个独立的算子称之为window,窗口函数的窗口数据定义由over关键字中的partition by字段和order by字段共同决定。当一个select语句中包含多个窗口函数,它们的数据窗口可能相同,也可能不相同,只有分区和排序都一样才是相同的数据窗口。对于窗口相同的窗口函数可以在同一个window算子中执行,对于窗口的窗口函数,优化器会将它们分成不同的window算子,每次执行之前都要重新分区和排序,且这些window算子必须串行执行,如下图所示。
5.2 串行窗口函数优化实例
以如下使用窗口函数计算两个排名的sql为例,通过explain执行计划可以看出两个窗口函数是顺序执行的,可想而知当窗口函数数量增多,计算时间也会正比例增长。
1 | explain |
执行计划如下,两个window算子分别在satge-1和stage-2中,这两个stage为父子关系:
1 | Explain |
使用union all+sum() group by对上述sql进行改造如下,则union all上下的两个select可以并发执行,实现了window算子的并发执行。这种方法的并发度更高,执行速度更快,但是对计算资源的要求也更高。
1 | explain |
执行计划如下,两个window算子分别在stage-1和stage-3中,这两个stage并发执行:
1 | Explain |