ClickHouse_ClickHouse按本地表推数组件原理与代码实战
1.组件流程
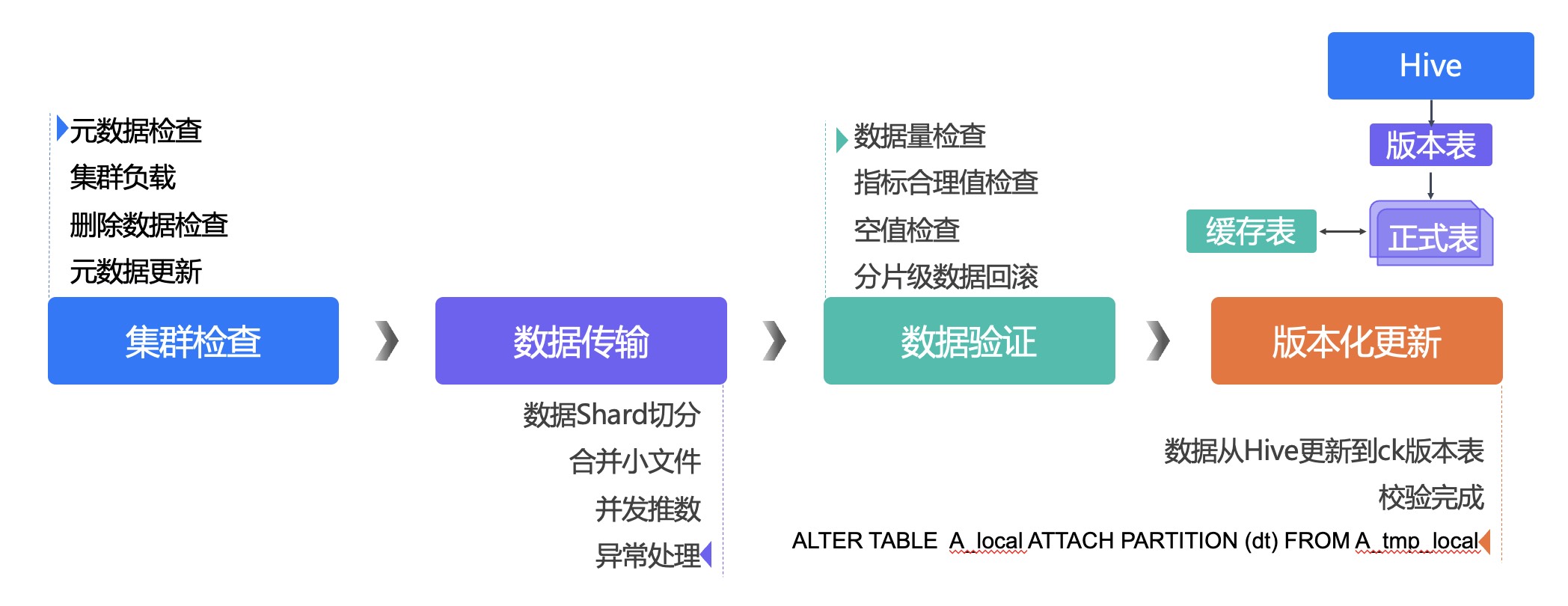
1.1 集群检查
元数据补全
根据hive表schema信息,字段类型自动映射成CK表类型,支持自定义分区、表字段函数生成新的DataFrame,使用on Cluster方式创建CK本地表和分布式表。
集群负载
调用集群普罗米修斯监控接口或者直接查询集群相关系统表,获取集群中是否存在cpu低于80%、内存低于70%、负载低于峰值60%副本集合,如存在,则按资源等级动态降低并发,直至暂停推数,以保障推数期间ck集群稳定使用。
查询system.query_log表可以获取当前正在执行的sql以及memory_usage内存使用情况,查询system.asynchronous_metrics读取cpu负载情况。
删除数据检查
要推数的分区在写数之前需要先确保数据已清空,删除后通过count计算分布式表查看数据是否已删除完成。
元数据更新
CK更新本地表,根据用户新加字段类型、修改字段类型、删除字段类型,执行相应DDL SQL on cluster,完成更新,分布式表自动删除并映射新的本地表创建分布式表。
1.2 数据传输
数据切分
挑选离散度较高的字段作为分片字段,常用skuId、用户pin等,在sparkRDD中将数据按照分片字段进行repartition,每个partition向同一个节点上的本地表中写入数据,这样即保证了所有节点的数据是均衡的,同时减少网络开销,提升数据写入速度。

并发推数
必要情况下可以将数据再进行细分,开启多副本同时写数。
异常处理
在hive中正确的数据,ck中可能由于数据类型等原因无法正确导入,捕获异常数据的同时,打印出来并进行计数,上游优化数据或者舍弃ck无法导入的数据,Counter值,在最后的验证环节提供数据支撑,保证源数据量=ck中数据量+异常数据量。
1.3 数据验证
数据量检查
推入ck的数据量 = 源数据量 - 异常数据量
指标合理值检查
选择需要验证的指标,uv、pv等指标除双11、618期间,增长一般不超过大促峰值,超过阈值告警,上游需检查数据是否正确。
2.代码实战
运行主类
1 | package com.jd.clickhouse |
写数RDD逻辑
1 | package com.jd.clickhouse.spark |