京东商智_基于ClickHouse预计算架构
一、背景两问
为什么要做ck2ck预计算,而不是hive2ck?
1.Spark引擎预计算,相对运算速度慢、资源按使用计费;
2.额外的数据传输损耗与精确去重资源损耗。
为什么不直接建物化视图和projection?
1.物化试图不支持基于分布式表直接建立分布式视图,也就是不支持跨节点物化加速,也不支持自定义跨分区物化加速;
2.projection也不支持跨分区、跨节点进行物化加速。
使用物化视图和projection无法加速数据到直接使用的kv粒度,仍然需要在消费查询时进行加和、去重等聚合操作。
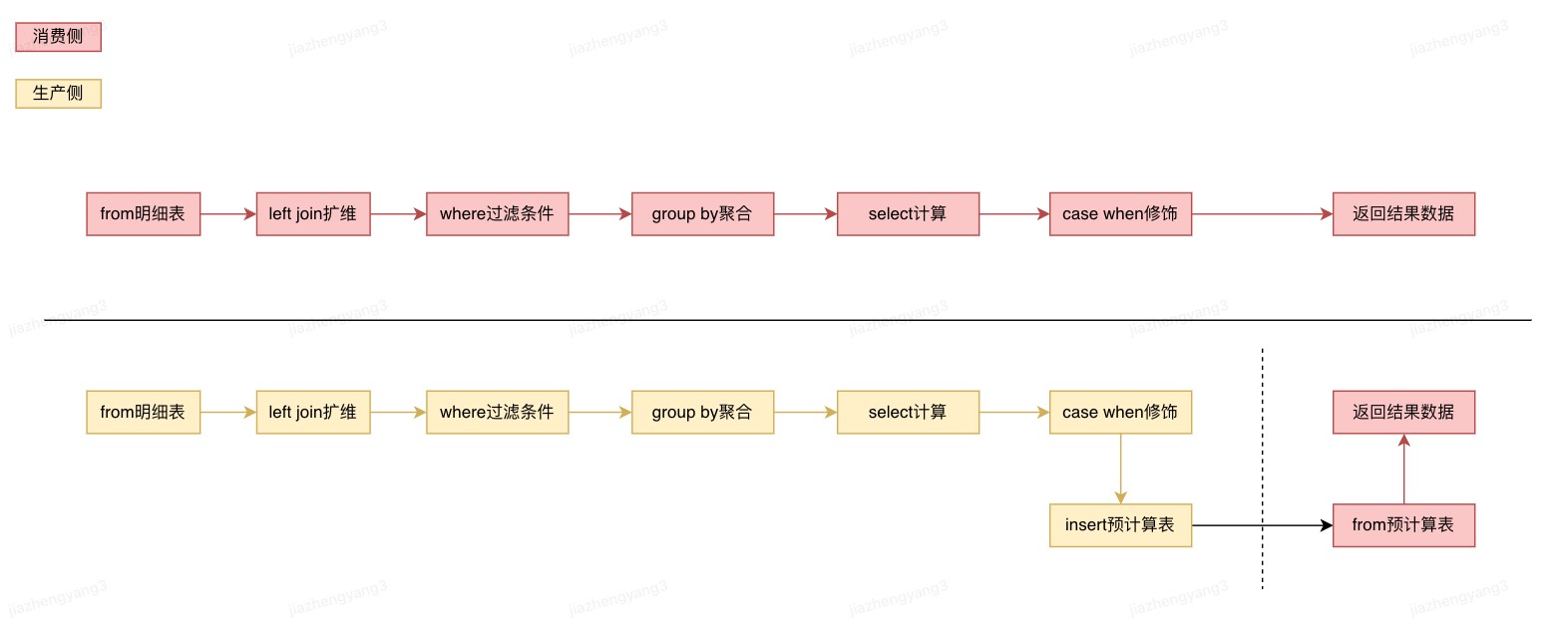
二、预计算生产与消费的建设思想
基于明细数据的olap查询,从用户请求那一刻开始将最细粒度的明细数据进行读取、过滤、聚合,最后渲染展示给用户;预计算就是将读取、过滤、聚合步骤提前做好,待用户请求时只需要读取少量数据并渲染展示给用户。
在定义驱动工程中,消费链路将基于明细查询链路进行了抽象和配置产品化;预计算生产链路即将部分过滤、聚合逻辑的具体实现提前执行了。总而言之,将从明细数据开始的定驱消费链路比作一条里程碑时间线,那么生产已经前置完成了部分里程碑,基于预计算数据开始的定驱消费链路只需完成后续未完成里程碑即可。
三、预计算生产开发逻辑细节
1.【meta-data-center】配置侧元数据定义
配置保存加速策略时,生成一张供消费侧可路由、可查询的预计算结果表。
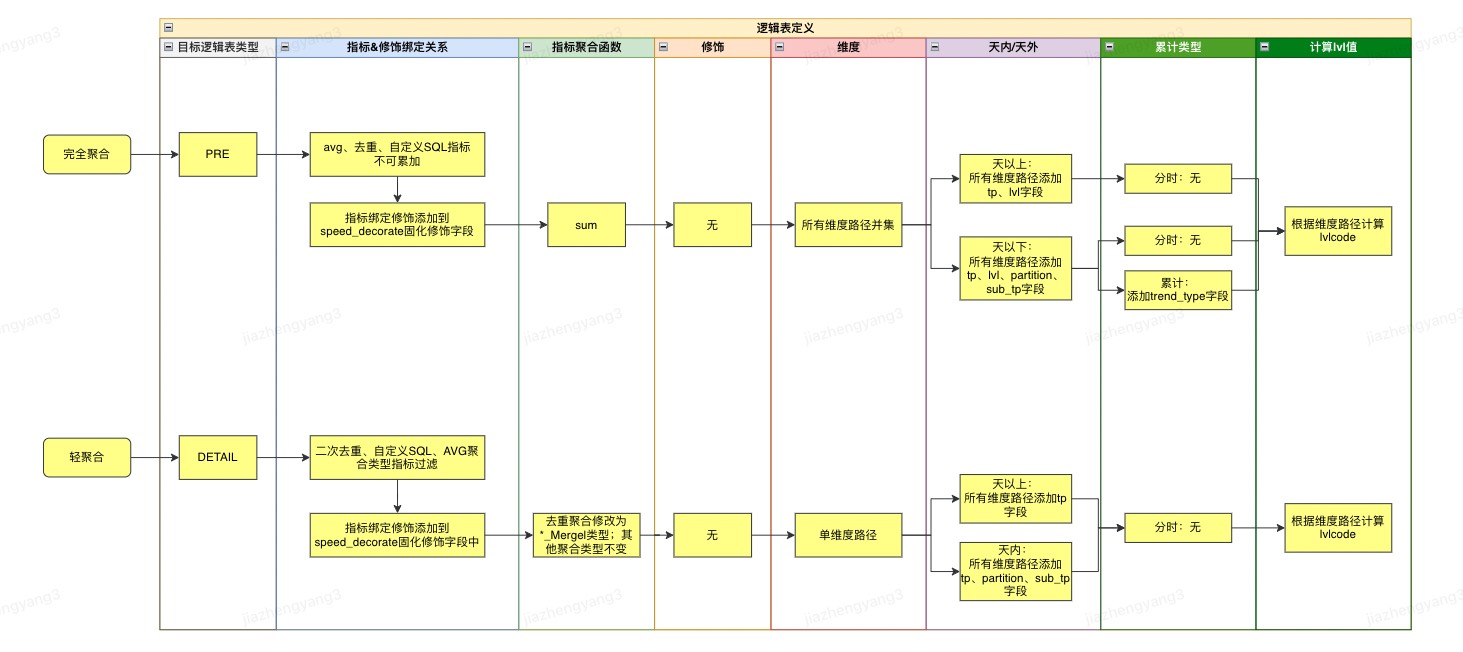
- 逻辑表类型:对于ClickHouse非中间态预计算和HBase预计算无变化,目标逻辑表类型logic_table_sub_type仍为PRE类型;对于ClickHouse中间态预计算,目标逻辑表类型logic_table_sub_type修改为DETAIL类型,表示基于该预计算目标表仍可进行聚合查询。
- 指标可累加属性:预计算目标表的avg、去重、自定义SQL指标不可再进行累加,其他指标可以继续供消费侧上卷累加;轻聚合目标表的avg、二次去重、自定义SQL指标直接过滤掉,不进行加速并提供消费。
- 指标&指标修饰绑定关系:只为目标逻辑表添加用户指定的’指标@固化修饰’列表对应指标;将用户指定的固化修饰list存储到unify_drive_logic_table_metric_relation的inherent_speed_decorate_id_list字段中。
- 指标聚合类型:对于ClickHouse非中间态预计算和HBase预计算无变化,目标逻辑表指标类型aggregation_type仍写死为SUM类型,aggregation_sub_type仍写死为空;对于ClickHouse中间态预计算,目标逻辑表指标类型aggregation_type保持与源逻辑表中的指标一致,对于非去重聚合方式aggregation_sub_type保持与源逻辑表中的指标一致,对于去重聚合方式aggregation_sub_type修改为*_Merge类型。
- 累计类型:全周期累计在所有维度路径中添加trend_type标准维度之后计算lvlcode,用于与分段累计进行区分。
2.【meta-data-center】生产调度SQL自动拼接
根据每日增量的明细数据,周期调度生成进行预计算生产的SQL,该生产SQL与基于明细的消费SQL基本一致,只不过需要新增一些预计算标识字段。
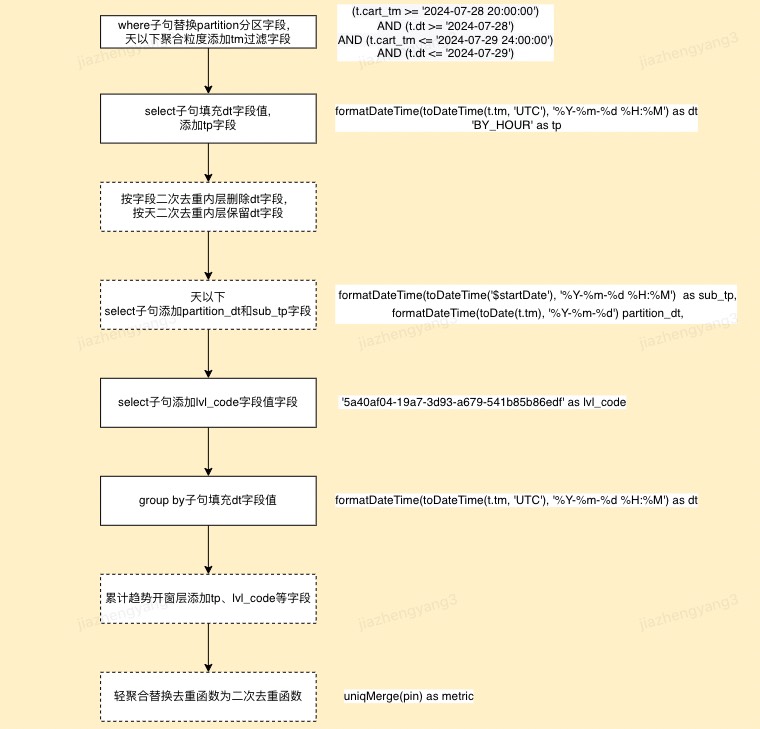
- where子句:如果源表配置了partition分区,则使用partition分区字段作为日期过滤条件;如果是天以下聚合粒度,则添加秒粒度时间过滤条件。
- select子句:按照BY_WEEK、BY_LAST_DAY_7等不同的聚合粒度填充应该实际存储的dt字段值,并添加tp字段。如果是二次去重,需要注意按照二次去重类型判断内层SQL中的dt是否保留。
- select子句:天内粒度需要添加计算开始时间作为sub_tp三级分区字段、还要添加时间字段的裁剪日期作为一级日期分区字段。
- select子句:添加到lvl_code字段并根据预计算维度路径计算lvl_code值。
小时粒度晚8累计生产sql案例:
1 | SELECT * |
3.【decision-task-container】执行预计算SQL并确保数据准确
采取内存溢出磁盘、分片散列等方式克服ck预计算的内存资源瓶颈,并完成数据校验保证生产数据准确性。
ck2ck预计算insert select语句写入数据(调整自定义超时时长、内存溢出、并发数等参数settings max_execution_time = 600, max_threads = 1, max_memory_usage = 60000000000, max_bytes_before_external_group_by = 30000000000)
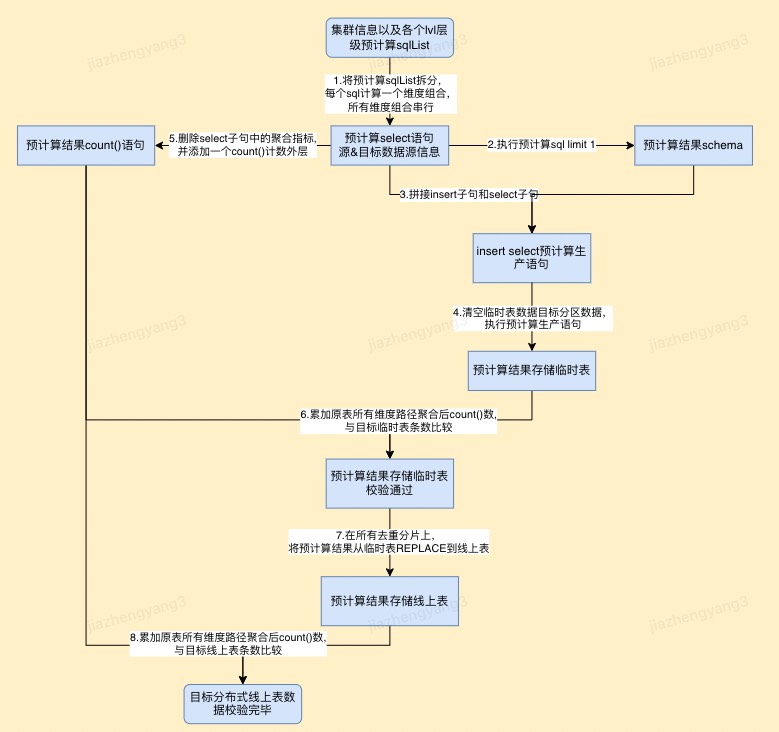
- 将预计算sqlList拆分,每个sql计算一个维度组合,所有维度组合串行;
- 执行预计算sql limit 1,获取预计算结果数据schema;
- 拼接insert子句和select子句作为完整生成sql;
- 清空临时表数据目标分区数据,执行预计算生产语句,将预计算结果写入临时表;
- 删除select子句中的聚合指标,并添加一个count()计数外层,作为源表预计算行数获取sql;
- 执行源表计数sql,累加源表所有维度路径聚合后count()数,与目标临时表数据条数比较;
- 在所有去重分片上,将预计算结果数据从临时表REPLACE到线上表;
- 执行源表计数sql,累加源表所有维度路径聚合后count()数,与目标线上表条数比较;
- 清空临时表数据目标分区数据。
ck2hbase预计算采用spark分片散列迁移数据(切分高基维度分节点执行分布式select语句)
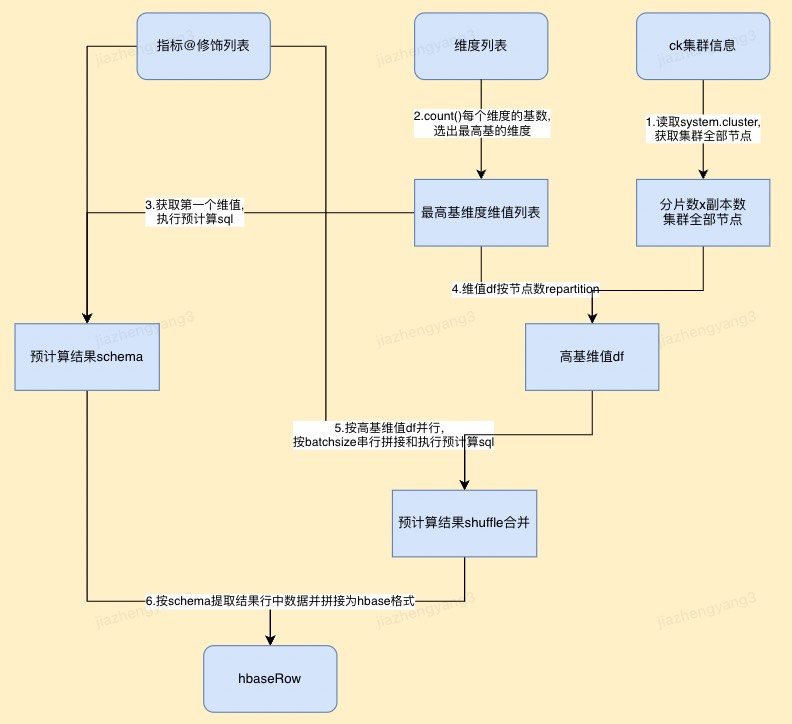
- 读取system.cluster,获取集群全部节点;
- 执行维度count()语句,获取每个维度的基数,选出最高基的维度;
- 获取预计算sql limit 1,获取预计算结果数据schema;
- 使用spark读取高基维值df,并按节点数repartition;
- 使用spark将按高基维值df分区并行,每个partition中按batchsize串行拼接和执行预计算select sql;
- 按schema提取结果行中数据并拼接为hbaseRow格式,进行bulkload写入HBase表。
四、关键代码入口
预计算加速策略与目标逻辑表元数据定义:
com.jd.bdaa.arch.controller.DriveSpeedUpStrategyController#speedUpStrategyAdd
获取生产SQL:
com.jd.bdaa.arch.service.impl.DriveDecisionEngineServiceImpl#translateSql
ck2ck计算脚本:
preCalculation/bin/python/task/ck2ck_distributed.py
preCalculation/bin/python/task/ck2ck_local.py
ck2hbase计算脚本:
preCalculation/bin/python/task/ck2hbase.py