HBase_HBase基础概念
1.什么是预计算
预计算就是提前计算和存储中间结果,再使用预先计算的结果加快进一步的查询。在OLTP当中最常见的预计算就是关系型数据库(mysql)中的索引;OLAP当中最常见的与计算就是HBase中的预分区。预计算以空间换时间,如果追求响应速度,优先考虑预计算;预计算增加了数据准备的时间和成本,减少了数据服务的时间和成本,如果追求高并发,有限考虑预计算。
OLAP(联机分析处理)就是基于数据仓库进行复杂的数据查询与分析。
OLTP(联机事务处理)就是基于传统的关系型数据库进行数据增删改查事务处理。
2.什么是HBase表倾斜治理?
数据存入HBase表时会按照rowkey落在不同的region中,rowkey在表中是按照ASCⅡ码排序的,每个region都有边界(除非你只有一个region)startrow和endrow。
region被regionserver管理,Hbase可以自动将region balance到各个regionserver上,使得每台regionserver上region的个数均匀分布。但是有一种极端情况就是,一张表的大部分region都在同一台regionserver上,这也算是一种HBase数据倾斜。为了避免这种情况的出现可以通过base.master.loadbalance.bytable设置表级别均衡。
那么最常见的就是细化到rowkey粒度的HBase数据倾斜,HBase框架自身没有提供能够解决这种问题的方法,只能通过我们自己设计随机散列+预分区的策略来解决。
3.为什么创建表时不预分区会导致HBase数据倾斜?
最开始Start-end key没有边界,所有数据都存储在同一个region,当数据增加达到split阈值,HBase框架会自动找到一个midkey将region一分为二。那么小于midkey的行存入region1,大于midkey的行存入region2。接下来存入的行的rowkey依然是顺序增大,那么只会往region2中写入数据,region1就被冷落,始终处于半满状态。以此类推,会不断产生被冷落且半满的region。这就导致了数据倾斜和热点问题,导致集群的资源得不到很好的利用。
4.HBase物理存储结构中Memstore与storefile有什么区别?
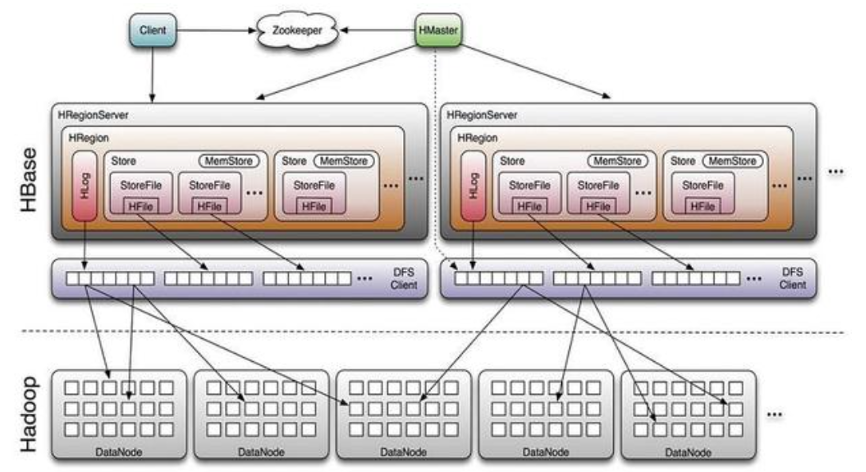
一张hbsae表根据rowkey排序按行分割成不同的region,每个region中按照列簇分割成不同的store。一个regionserver上可以存储多个region。一个region上可以存储多个store,但是越少越好。
Region中的每个store存储了一个列簇的数据,store包括位于内存中的memstore和位于磁盘中的storefile。HBase执行写操作时先写入memstore,当memstore中的数据达到某个阈值,regionserver就会启动flashcache进程将memstore中的数据写入一个新建的storefile文件。当一个store中的storefile数量增长到一定阈值之后,系统会对它们进行版本合并和删除工作(minor compaction、majar compaction),形成更大的storefile。当一个region中所有storefile的大小和超过一定阈值之后,就会进行region-split,并自动由master分配到其他regionserver实现负载均衡。
每个store由一个memstore和0到多个storefile组成,客户端查询数据时,先在memstore中寻找,找不到再找storefile。Storefile是以Hfile格式保存在HDFS上的。
5.HBase中minor compaction与majar compaction有什么区别?
Minor compaction是将一系列hfile合成一个hfile,合并的文件数目是可以配置的,合并时间与频率也是可以配置的,被合并文件一般是最老的几个符合要求的hfile。同时只会清理过期数据。
Majar compaction是将一个Region下的所有hfile合成一个hfile,合并时间和频率是可以配置的。同时会清理掉过期版本、多余版本、被删除的数据。
HBase的数据删除操作,是先搜索数据在不在memstore,在就直接删除,不在就把删除数据标识记录在memstore中,等待majar compaction时再删除。
Compaction的主要目的是提高读性能,并不能提高写性能。
Compaction主要由两种触发时机,一是在memstore刷写之后判断是否达到合并条件,二是通过CompactionChecker线程周期轮询是否达到合并条件。
6.HBase的rowkey设计时应该遵循什么原则
唯一性原则、长度原则、散列原则三大原则。
长度原则:rowkey是一个二进制码流,可以是任意字符串,最大长度64kb,实际应用中一般为10-100bytes,以byte[]形式保存,一般设计成定长。建议设计得越短越好,不要超过16个byte。因为Memstore和Hfile中的数据都是按照keyvalue存储的,键占用空间太多就会导致内存和硬盘中存储的value数据减少,降低检索效率。
散列原则:rowkey不要随时间递增,常用散列方式有加盐、哈希、反转、时间戳反转。
7.HBase推数
HBase主要用于解决大数据实时查询问题,但是在使用过程中会有短时间内推入大规模数据存在性能瓶颈的问题,比如使用API调用方式进行周期性(如每天)推入大规模数据时。
那么现在常用的写入HBase的方式主要有三种:
- 调HBase API,使用Table.put方法单条写入;
- MapReduce方式,使用TabelOutputFormat作为输出;
- BulkLoad方式,先将要推入的数据按照格式持久化为Hfile文件,然后使用HBase对该文件进行load。
在Spark环境下使用bulkload方式能够极大提高hbase推数效率,主要步骤如下:
- 使用hive读取数据;
- 利用spark集群对数据进行加工,并定义rowKey,对数据进行排序;
- 利用ImmutableBytesWritable组织数据;
- 利用HFileOutPutFormat2将数据以HFile文件的方式写到HDFS目录上;
- 利用LoadIncrementalHFiles工具将HFile加载到hbase上。
bulkload的本质就是两步:从某处数据库中提取出数据进行排序计算并保存在hdfs中->将hdfs中的排序文件推送到hbase目录当去。
8.HBase结构中的HLog有什么作用?
HLog中保存了数据操作日志,在regionserver宕机时根据HLog进行丢失数据恢复。
9.什么是HBase预分区?
hbase当中的rowkey是按照ascii码来进行排序的,一张hbase表的region分区是按照rowkey来分的,每个region都有startkey和endkey,该region中保存的数据的rowkey都在这两个key的范围内。
如果不进行预分区,hbase表创建时默认只有一个region,在数据写入较为频繁时,spilt也会较为频繁,spilt比较耗时耗资源,所以我们一般会在建表时进行预分区。
预分区就是设置一定数量的key,比如要创建10个预分区,就设置9个key。那么0到第一个key就是第一个region的startkey和endkey,依此类推。
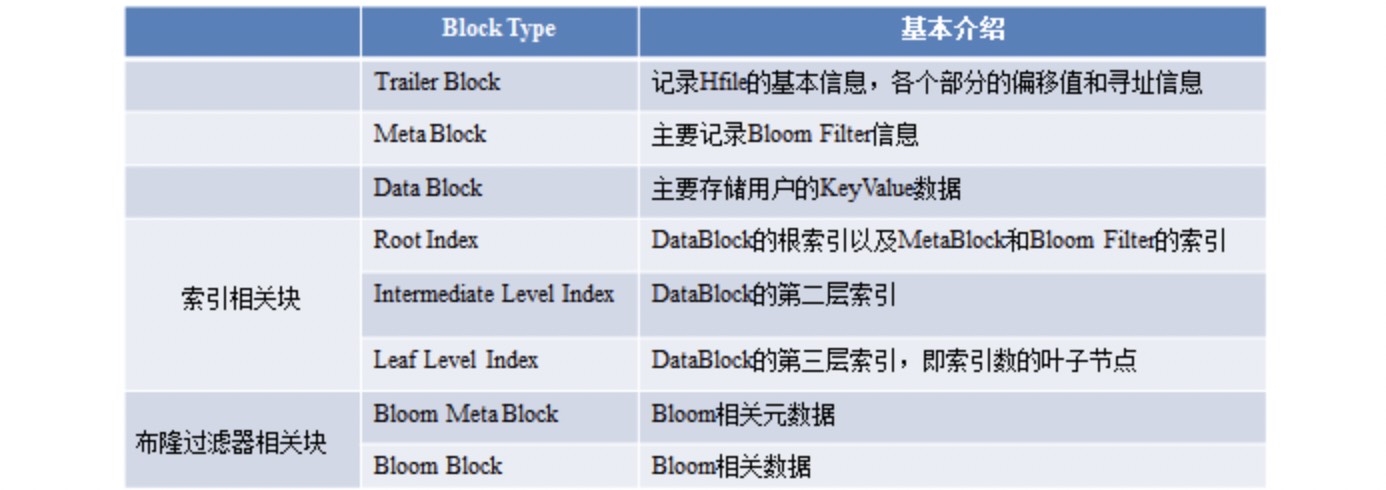
10.HFile的物理存储结构?
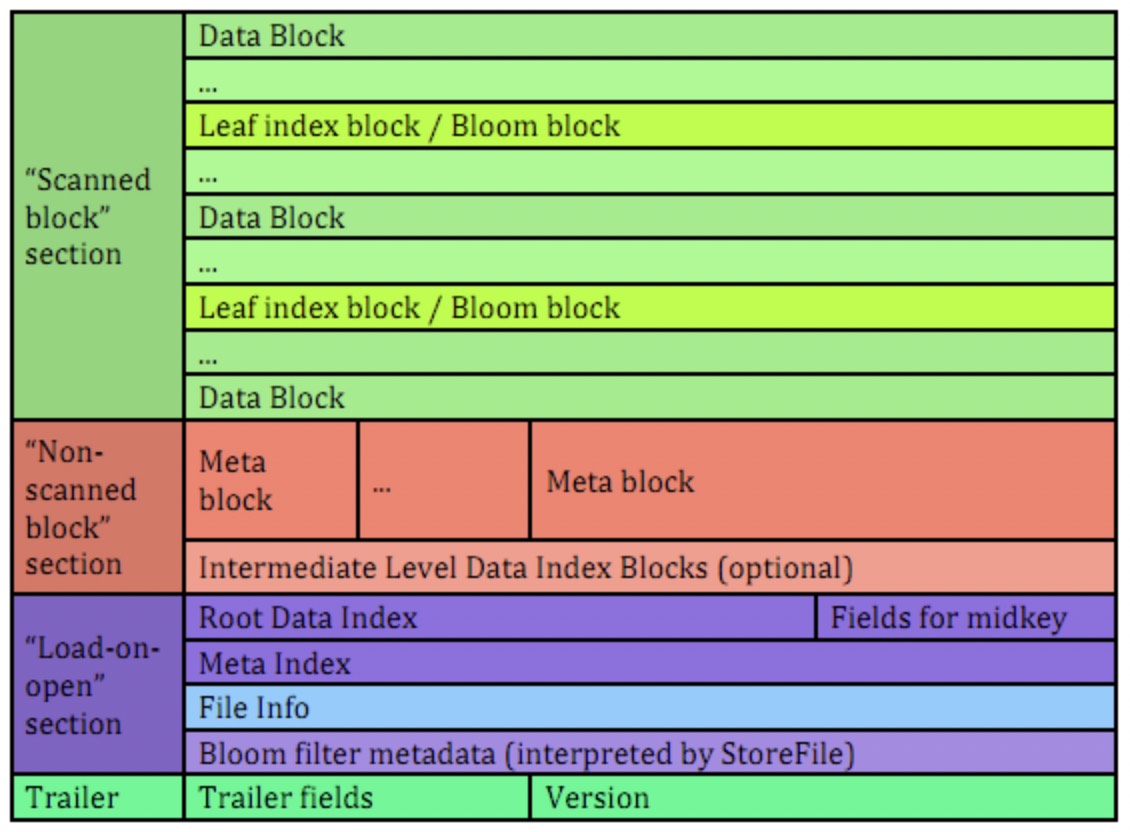
如上图所示,hfile v2在逻辑上的结构主要分为四个部分:
- 扫描时会被读取的部分;
- 扫描时不会被读取的部分;
- regionserver启动时会被加载到内存中的部分;
- 尾部:主要记录hfile的版本信息、各部分的offset。
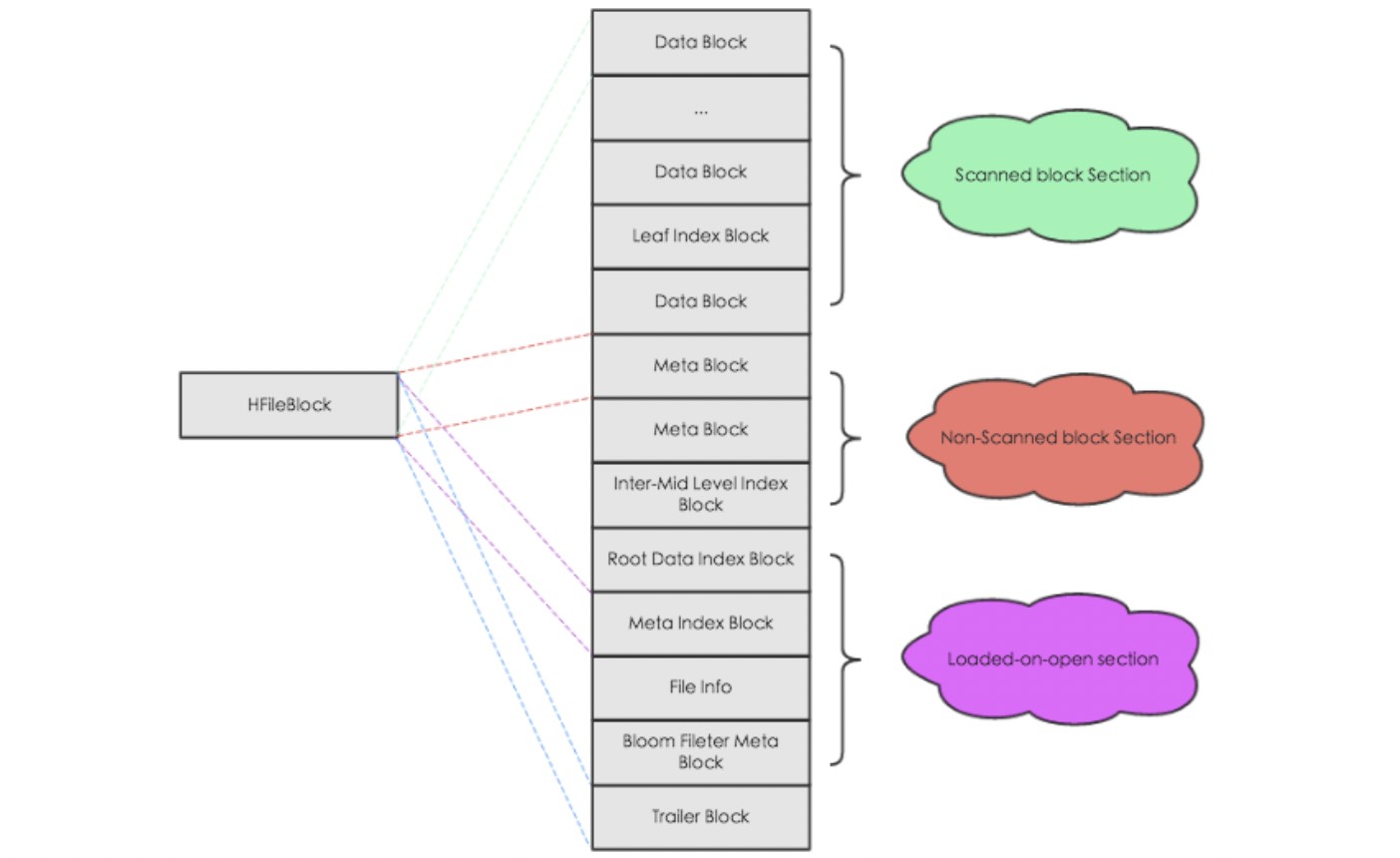
hfile在物理上的结构如上图所示,是被切分成一个个大小相等的block块,block块的大小可以在建表时通过参数blocksize制定,默认是64kb,而且所有的block内部结构都相同。
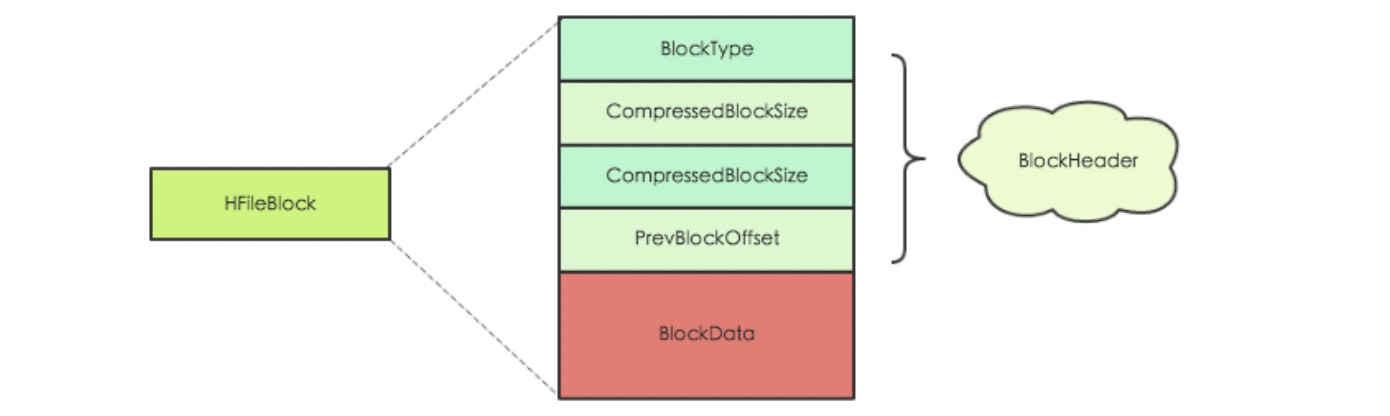
block的结构如上图所示,其中blocktype是最重要的字段,用来表示block块的类型。hbase定义了8中blocktype,如下图所示。每一种不同类型的block中,都有结构不同但是固定的blockdata,其中最有意思的就是布隆过滤器block。
11.namespace
HBase的命名空间namespace特性是对表资源进行逻辑隔离的一种方式,类似于mysql中的database,方便对表进行业务上的划分。
namespace可以通过hbase api来创建、删除、修改,hbase中namespace和table的隶属关系在建表时决定,通过namespace:table的格式来指定。当为一张表指定命名空间之后,对表的操作都要加命名空间,否则会找不到表。
hbase中有两个默认创建好的namespace,分别是hbase和default:
- hbase:该命名空间用于存放hbase的内部表;
- default:所有未指定命名空间的表都自动存放在该命名空间中。