HBase_HBase自定义带版本因子timestamp与行粒度TTL专利与实战代码
一、专利撰写
一种自定义行粒度生命周期的HBase表大批量数据写入方法
技术领域
本发明属于HBase数据库技术领域,具体涉及一种为每一行数据设置不同timestamp和cell TTL(time to live)的HBase表大批量数据写入方法。
背景技术
HBase是一种非关系型数据库,具有高性能、高可靠性、分布式、可伸缩等特点,非常适合存储非结构化数据。HBase数据库构建于Hadoop分布式文件系统之上,在物理存储上借助列簇实现KV(Key-Value)数据的存储,底层通过HDFS副本机制实现数据的冗余存储,具有极其出色的读写性能。
HBase支持列簇粒度TTL和单元格粒度TTL。TTL的作用原理:系统当前毫秒级时间戳currentMilliseconds减去单元格时间戳timestamp 的差值大于TTL,则判定该单元格过期,无法被查询返回,在数据合并时被删除。列簇粒度TTL和单元格粒度TTL可以同时设置,系统按照最小的TTL来判断单元格数据是否过期。
数据应用平台为了应对高并发场景下的数据查询请求压力,通常将明细数据按照设定的维度路径和指标口径进行预计算后以KV的形式存储在HBase数据库中。为了提供更加灵活和全面的数据展现形式,对于具有固定业务口径的一块数据看版,通常会提供单天、周至今、近7天、小时等不同聚合时间粒度的预计算数据供筛选切换,也会提供类目、品牌、商品等不同聚合维度路径的预计算数据供筛选切换。将这些时间粒度、维度路径等具有不同业务含义的聚合数据变化情况与营销、推荐等策略进行结合分析,即可帮助数据应用平台用户更加快捷、方便地了解数据影响因素,针对性地制定数据表现提升方案。
数据应用平台使用多种多样的聚合时间粒度和维度路径预计算数据为用户提供灵活的时间范围和聚合维度选项,这些具有相同指标口径的数据通常存储在同一张HBase表中,只需要根据传入的聚合时间粒度类型和聚合维度枚举,即可区分具有不同业务含义的数据。针对该HBase表只需要在数据服务中建立一个数据模型,通过传入不同聚合维度组合和对应维度过滤值即可方便快捷地获取对应聚合数据,实现了模型口径唯一、服务开发便捷、高效查询、响应速度快等优点。但是在实际业务过程中,同一张HBase表中具有不同业务含义的预计算结果数据通常具有不同历史周期查询优先级,如部分业务数据历史周期的查询概率较高则需要存储较长周期,而部分业务数据历史周期的完全不会被查询到,随着业务模块的不断增加,HBase集群占用存储资源增长迅速,集群无法进行无限制的扩容;且每次新上业务需求进行历史数据回溯都会造成HBase数据生命周期计算起点时间戳timestamp刷新,导致历史数据无法按照预设生命周期及时过期清除,需要再等待一整个HBase列簇粒度TTL才能被真正清理。
鉴于上述HBase数据库业务增长与存储现状,有必要针对存储无限制增长和数据冗余严重问题,在满足用户看数需求和数据存储成本中寻找一个平衡点,抑制存储增长,进行存储治理。同一张HBase表中具有不同业务含义的数据可以设置不同TTL,业务调整带来的历史回溯数据也应该按照业务时间正常过期。因此,设计一种针对同一张HBase表中不同业务含义数据行设置不同timestamp和cell TTL的大批量数据写入方法,显得十分迫切和重要。
发明内容
本发明的目的是克服现有技术的不足,提供一种针对同一张HBase表中不同业务含义数据行设置不同timestamp和cell TTL的大批量数据写入方法,该方法能够有效缓解HBase集群存储无限制增长和数据冗余严重的问题。
为了克服现有技术问题,本发明是通过以下技术方案实现的:
1)一种针对同一张HBase表中不同业务含义数据行设置不同timestamp和cell TTL的大批量数据写入方法,特征在于数据集市应用层按照各种业务维度组合和聚合时间粒度预计算得到各个不同业务层级的结果数据,存放在Hive表中,采用MapReduce计算引擎并发读取Hive结果表的数据文件。
2)按上述技术方案,所述MapReduce计算任务的Map阶段,每个Task读取一个Hive表存储文件,逐行读取Hive表存储文件中Text格式的预计算结果数据行,解析出字段数据并计数。
3)按上述技术方案,所述MapTask解析提取出能够标识结果数据行唯一性的所有聚合维度字段值,这些维度值按照指定顺序拼接在一起能够具有唯一的业务含义。
4)按上述技术方案,将所述能够标识数据行唯一性的聚合维度字段值按照从低基维度到高基维度的顺序排列,并将首个维度字段值进行反转散列再拼接,作为该数据行的Rowkey。
5)按上述技术方案,所述MapTask解析提取出业务生产时间datetime,并将其转换为毫秒级Unix timestamp,作为预计算结果数据行的业务生产时间戳。
6)按上述技术方案,将所述业务生产时间戳加上版本因子,作为该数据行的timestamp,所述timestamp计算公式如下: )式中
)式中 )为上述业务生产时间戳,
)为上述业务生产时间戳, )为推数任务运行时系统时间戳,
)为推数任务运行时系统时间戳, 为一个自然天的毫秒数。
为一个自然天的毫秒数。
7)按上述技术方案,所述MapTask解析提取出能够标识结果数据行在历史周期中业务新鲜度的维度字段值,根据这些具有不同业务含义的维度值确定该数据行在历史周期中的存储优先级。
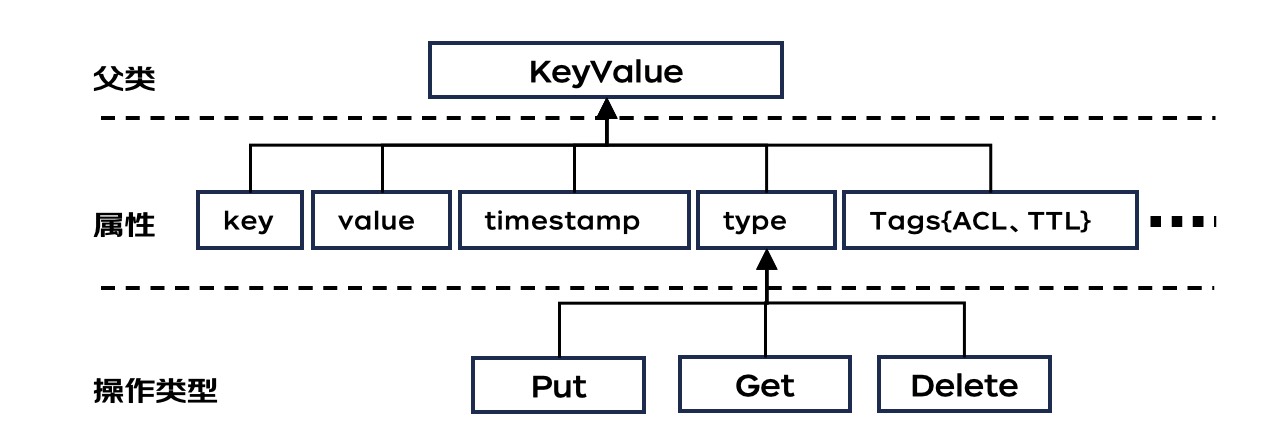
8)按上述技术方案,对上述历史存储优先级较高的数据行的设置较长的TTL,对上述历史存储优先级较低的数据行设置较短的TTL,将TTL封装为KeyValue对象的Tag属性。
9)按上述技术方案,将所述Rowkey、timestamp、TTL Tag作为对象属性组装成HBase的一个Put对象,一个HBase数据库格式的数据行可以包含具有相同Rowkey、timestamp、TTL Tag属性和不同value属性的多个Put对象。
10)按上述技术方案,所述MapReduce计算任务的Shuffle阶段,将Map阶段解析处理好的数据行根据Rowkey按照目标HBase表的Region切分点进行切分,发送到不同的Reduce节点上。
11)按上述技术方案,所述MapReduce计算任务的Reduce阶段,每个Task将其所收到的所有数据行根据Rowkey按照字典序排序,通过检验排序后相邻数据行的Rowkey是否相等来校验每个数据行的业务含义唯一性,当存在相邻数据行Rowkey相等则抛出异常,停止运行计算任务。
12)按上述技术方案,将所述解析处理、切分和排序判重完成后的HBase格式数据行按照指定压缩格式存入HFile文件中,可以通过参数指定ZSTD、BZIP2、LZ4等压缩格式。
13)按上述技术方案,将所述压缩HFile文件存储在HDFS集群的临时目录中,使用BulkLoad方式将所述HFile文件推送到目标HBase集群存储目录中。
14)按上述技术方案,将所述大批量数据写入方法将所述MapReduce计算任务Map阶段统计的解析数据行数与所述数据集市Hive表中数据行数进行比较,校验写入总行数成功后放开数据服务查询请求。
本发明提供的自定义行粒度生命周期的HBase表大批量数据写入方法与现有技术相比,具有以下有益效果:将组成Rowkey的首个业务字段进行反转散列并按从低基到高基维度排序再拼接,实现了HBase数据的均匀散列、避免聚集,同时还能实现灵活的业务维度组合前缀匹配查询;提取业务生产时间作为数据单元格timestamp,避免业务数据回溯时按照数据更新时间重新计算TTL造成数据存储冗余;为业务生产时间timestamp添加版本因子,确保数据单元格在更新前后业务生产时间不变的情况下,更新后的timestamp大于更新前的timestamp,避免数据更新失效;为同一张HBase表中具有不同业务含义的数据添加不同的生命周期,将不会再被使用的历史数据提前清理,缓解存储资源紧张问题;通过检验有序相邻数据行的Rowkey是否相等来确保每个数据行的业务唯一性,方便快速发现上游数据问题和响应;采用ZSTD等压缩格式存储HFile文件并直接推送到HBase集群存储目录中,传输速度快,占用带宽、存储资源少;比对写入目标HBase表数据行数和源Hive表数据行数,确保数据写入无遗漏。
附图说明
图1为本发明的整体流程示意图。
图2为本发明所述的HBase单元格自定义组装的属性。
图1:
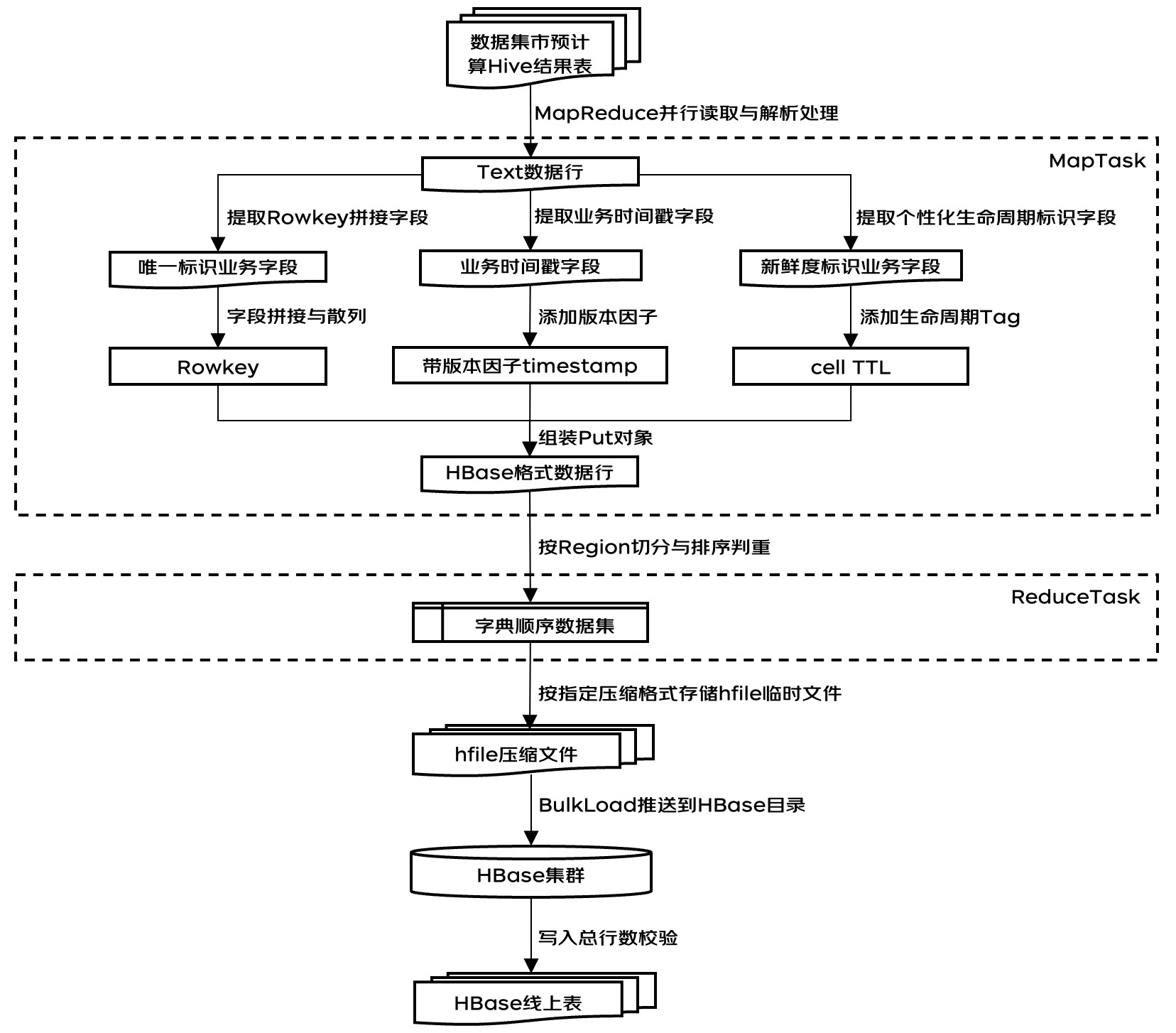
图2:
二、实战代码
1.Spark2HBase推数工具
注意此处目前在实际代码中有三处与上述专利内容存在差异:
1)此处使用Spark引擎替换MapReduce引擎,计算效率更高,且可以先进行逻辑运算再将存储在内存中的RDD数据直接进行解析转化写入HBase,而MapReduce引起只能直接读取Hive表数据文件;
2)此处没有给timestamp加上版本因子,是线上使用自定义timestamp然后进行数据回刷之后发现数据没有更新才暴露出的这个问题,后续才想到版本因子这个解法,但是还没真正写到代码中并应用到线上;
3)此处的rowkey没有采用首个业务字段反转的散列方式,而是采用前缀字段MD5的方式进行散列,数据均匀性好很多。
实战代码如下:
1 | object Spark2HBase { |