数据开发之离线计算_HIVE的mapjoin原理与夜间任务倾斜快速处理
一、夜间任务运行慢排查
1.任务运行情况查看
某天晚上值班,一个任务之前每天运行10min完成,这天1h还没有完成,查看日志和mr监控也没有任务报错,但是mr处理行数翻了100倍。
前一天:
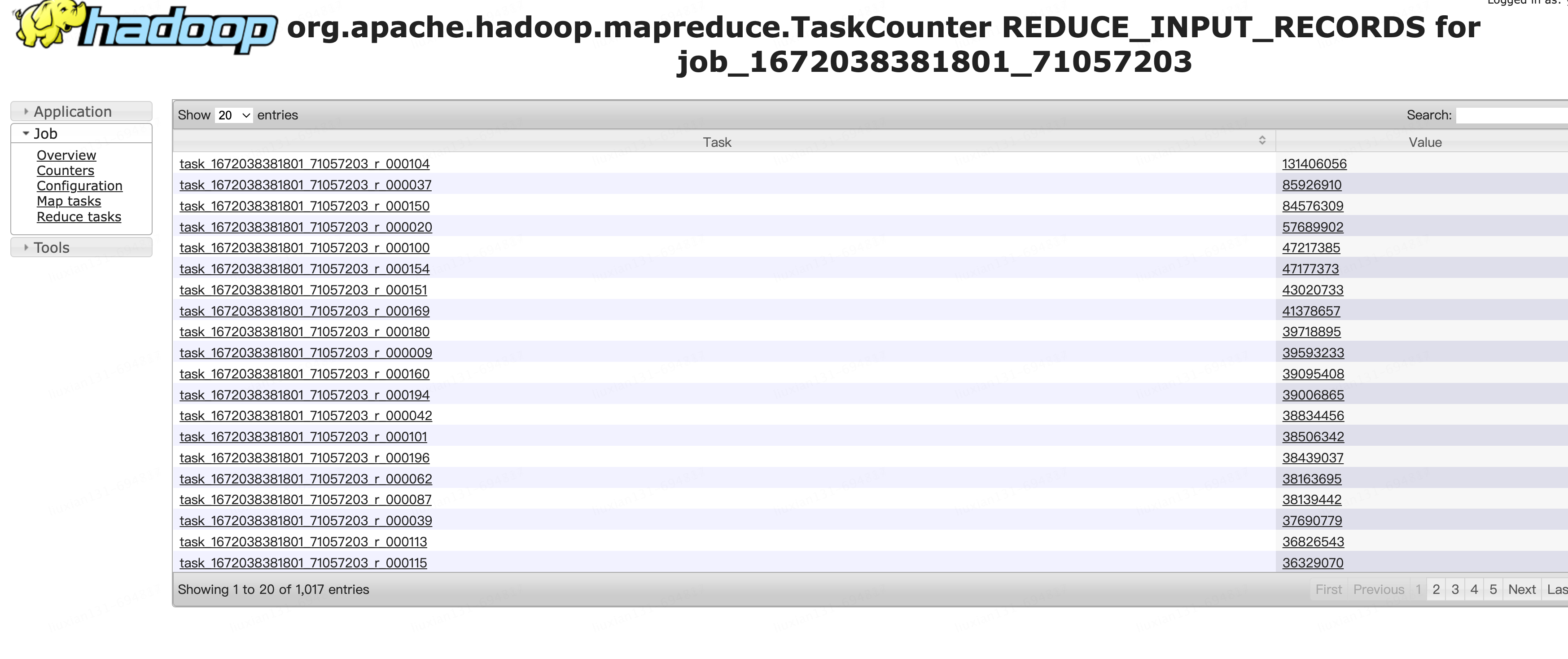
当天:
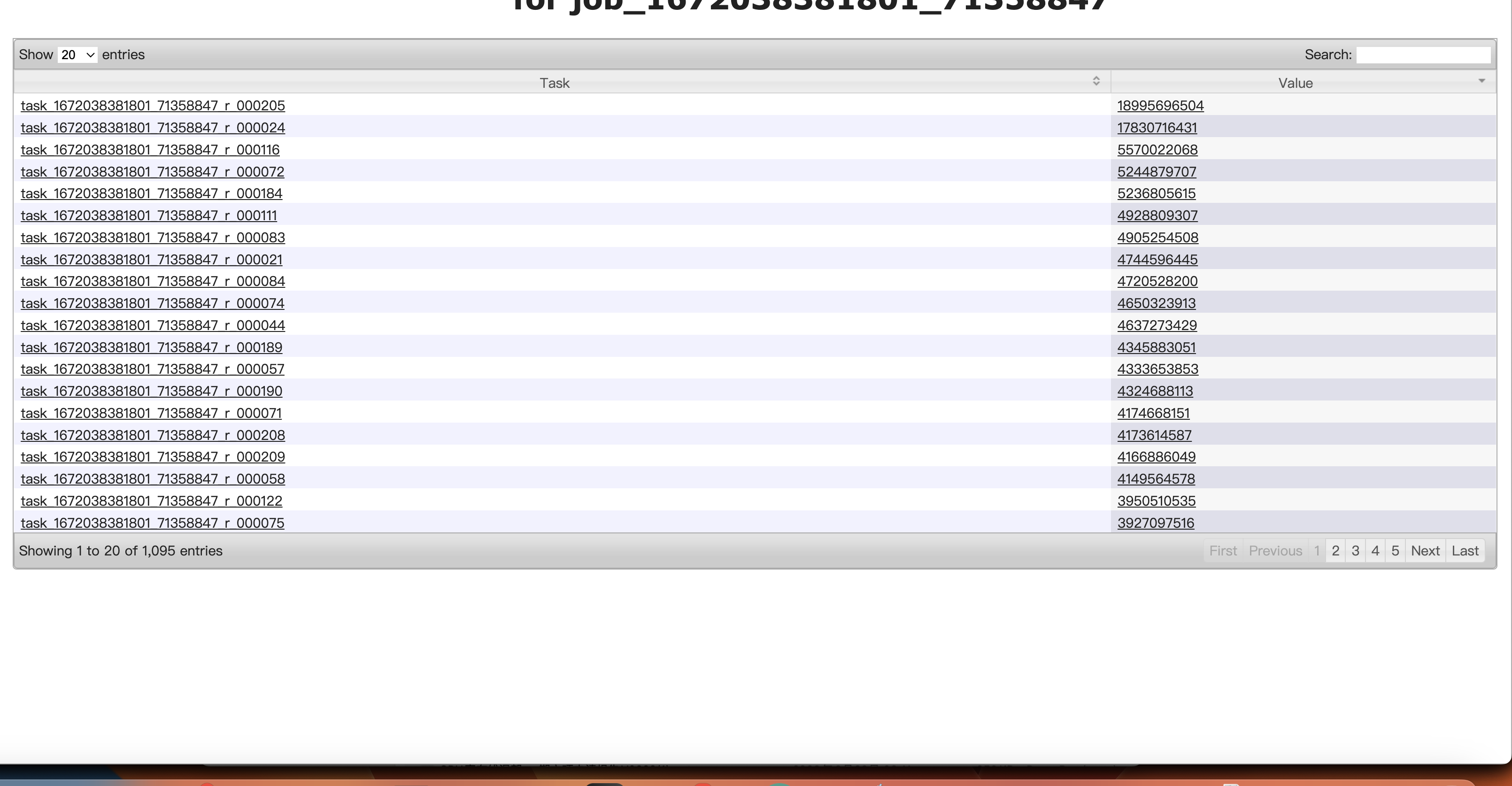
2.日志排查
在源表数据量变化不大的情况下,mr任务处理数据量变化这么大,首先怀疑的就是某些优化措施失效了,首先想到的就是mapjoin。
通过使用mapjoin关键字比较两天的执行日志,发现前一天mapjoin生效了,生效日志如下,今天日志里就搜不到这一条了:

再一看mapjoin小表阈值设置hive.mapjoin.smalltable.filesize=25000000也就是23.8M:

然后这个任务的关联小表的分区大小,昨天的分区大小正好是23.8M,今天就是23.9M了:
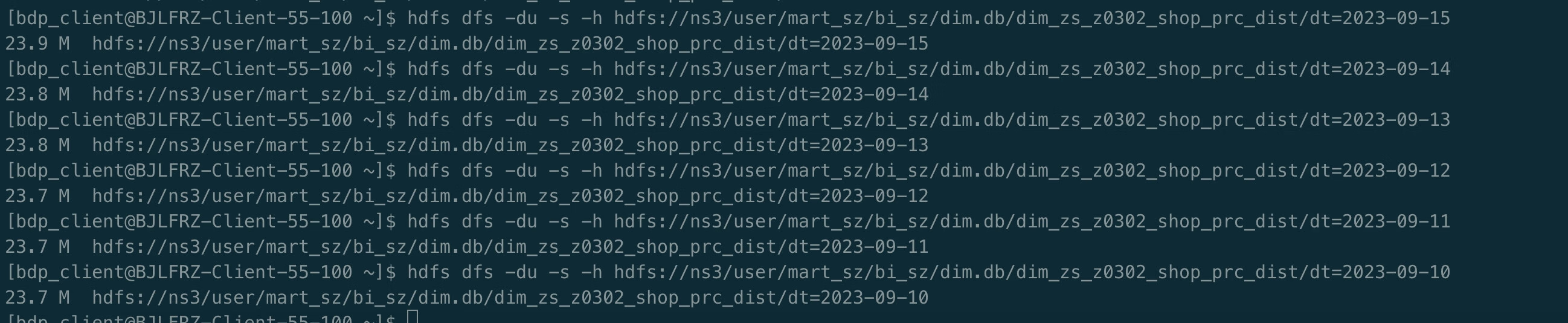
所以得出结论就是数据增长超出阈值导致mapjoin实效,然后任务倾斜严重。
3.解决方案
短期方案就是先将参数值调大set hive.mapjoin.smalltable.filesize=50000000,但是一般最大不能超过1GB。因为该维表是在不断增长,而不是在一定范围内波动,所以长期还是要做优化,如引擎切换、逻辑优化等。

二、MAPJION
Hive中的Join可分为Common Join和Map Join两种
1.Common Join
Common Join本质就是shuffle join,将左右表中数据分别按关联键进行分区,然后进行shuffle,在Reduce再进行数据映射与合并。如果不指定MapJoin或者不符合MapJoin的条件,那么Hive解析器会默认执行Common Join,即在Reduce阶段完成数据的关联合并。
2.Map Join
Map Join本质就是broadcast hash join,与spark中的broadcast hash join原理类似,把小表全部读入内存创建hash table。更重要的,MAPJION会在map阶段直接拿另外一个表的数据和内存中的hash table做匹配,相当于是在map端进行了join操作,而不需要将左右表的数据按关联键进行分区再在reduce阶段进行数据匹配关联,直接就没有reduce任务了。这样一来省去了Shuffle这个代价昂贵的阶段,二来避免了由于关联键数据倾斜造成的计算任务倾斜。
MapJoin通常用于一个很小的表和一个大表进行join的场景,具体小表有多小,由参数hive.mapjoin.smalltable.filesize来决定,默认值为23.8M,大于该值则不会使用MapJoin。满足上述条件的话Hive在执行时候会自动转化为MapJoin,或者在Hive0.7版本之前需要使用hint提示 /*+ mapjoin(smalltable) */来指定使用MapJoin。
如下sql:
1 | SELECT |
实际中hive.mapjoin.smalltable.filesize这个最大值参数可以修改,但是一般最大不能超过1GB。另外MapJoin也不适合full/right outer join。