HiveSQL实战积累_分时累计趋势图的多种实现方案与比较
分时累计趋势图定义
分时累计趋势图一般是指一天内的累积趋势图,与之对应的就是分时窗口趋势图。比如小时累积的24个点中第一个点就是0-1点的数据,第二个点就是0-2点的数据,每个点都是0点到该点的累积数据;小时窗口的第一个点就是0-1点的数据,第二个点就是1-2点的数据,每个点就是一个被等分的时间窗口中的聚合数据。
分时窗口趋势图比较好出数,直接按照时间前缀等方式group聚合即可,但是分时累计趋势图就比较麻烦了,总结常见的出数方式有下述三种。
流量模块预计算
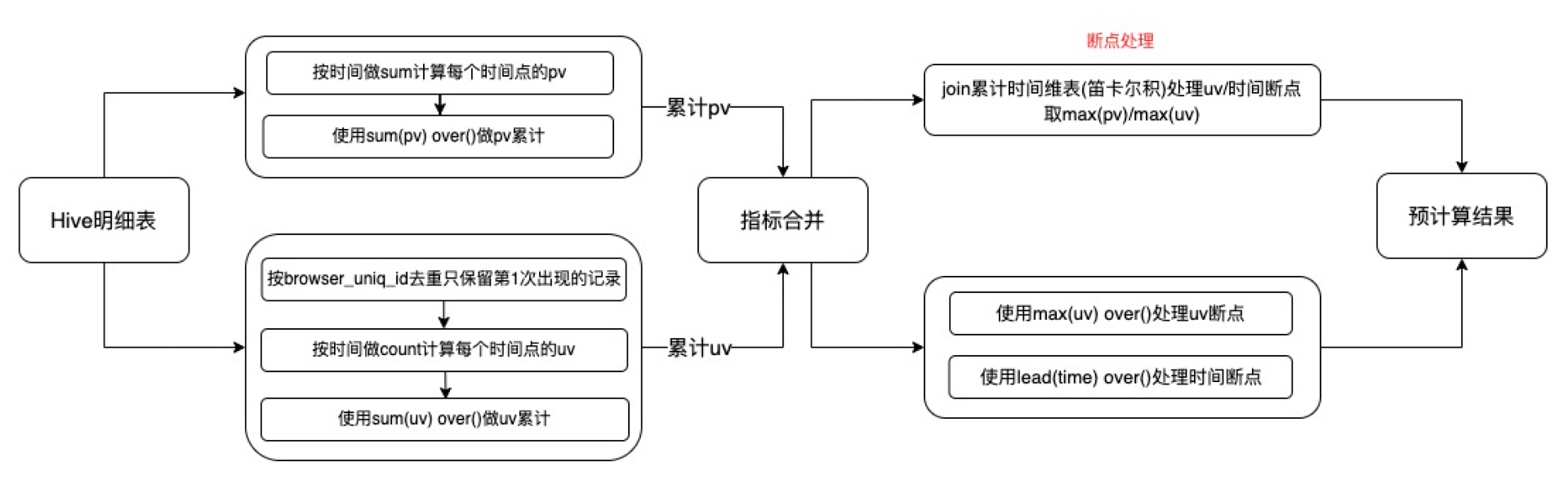
1 | SELECT |
上述预计算流程中,最关键的就是通过group by+min获取到每个用户的最早登陆时间,然后再通过窗口函数直接累加即可得到去重uv。
主要缺点:
- 计算流程复杂,对于去重和非去重指标需要分开按不同逻辑计算,存在多步聚合和指标关联操作。
- 存在较为明显的时间断点和uv断点,时间断点是指,某些时间区间内没有pv或uv,导致采用窗口函数累加得到的数据表中,没有该时间维度行;uv断点是指某些时间区间内有pv但是没有uv,导致累加完之后的两指标合并之后,该时间维度行的uv为0或空。这些断点在无论在数据还是服务层面都需要再关联时间维表来补全断点。
流量olap服务出数
1 | -- 常规写法 |
依赖clickhouse引擎的uniqState或者uniqCombinedState函数生成bitmap先计算分时聚合数据,然后再用开窗函数做分时累计。
主要缺点:
- 需要一层嵌套子查询。
- hive中不支持去重计数开窗函数,clickhouse利用了bitmap存储去重数据才支持的。
- 同样存在时间断点问题,需要在服务层中再关联时间维表补全断点。
交易模块预计算
1 | SELECT |
将明细数据关联时间维表或侧视图,然后通过where条件过滤出各个累计时间段内的明细数据。
主要缺点:
- 明细数据爆炸造成计算压力较大,加重数据倾斜,在十分和小时情况下数据分别膨胀144倍和24倍还能接受,但如果是分钟粒度或者秒级粒度数据量难以接受。
通用数据服务生产链路中暂定以lateral view关联时间维表的方式支持十分累计、小时累计两种预计算粒度。