大模型_SpringAI&Ollama&pgvector实现RAG本地实战笔记
一、相关工程
https://github.com/littleforestjia/ragdemo.git
二、环境准备
1.Embedding模型部署
使用Ollama本地部署embedding模型
1 | ollama pull mofanke/dmeta-embedding-zh |
Embedding在大模型中的价值
大白话讲清楚GPT嵌入(Embedding)的基本原理这篇推文对Embedding介绍的非常形象易懂。
以一个代表性的应用来说明,当我们想让大模型根据我们给定的pdf文档进行问题回复时,就可以对超长pdf进行分块,获取每个分块内容的embedding,并使用向量数据库存储。接下来,当你提出问题“xxx在文档中是如何实现的?”时,就可以使用你的问题embedding,去数据库中检索得到与问题embedding相似度最高的pdf内容块embedding。最终把检索得到的pdf内容块和问题一起输入模型,来解决新知识和超长文本输入的问题。
Embedding模型只支持512个tokens那怎么构建本地知识库?
如果你的embedding模型只支持512个tokens,但你需要建立一个本地知识库,这意味着你可能需要将知识库分割成小块以适应模型的限制。解决方案:
- 使用分词器将长文本分割成小块,每块不超过512个tokens。
- 将分割后的小块逐个输入到embedding模型中。
- 将生成的embeddings合并,通常可以使用平均池化或者最大池化。
2.pgvector向量库部署
部署方案
本地安装linux系统虚拟机,虚拟机中安装docker,docker运行pgvector镜像。
虚拟机使用sudo su命令切换到root用户命令,这样才可以执行docker命令。docker拉取pgvector向量库镜像命令和运行命令如下:https://blog.csdn.net/u011788214/article/details/136470300
1 | docker pull pgvector/pgvector:pg16 |
工程访问方式
本地访问pgvector镜像:
1.本地如何连接虚拟机:在虚拟机上执行ifconfig命令获取到虚拟机的lo本地回环地址(用于在虚拟机内部访问服务);获取到ens160虚拟机网络地址(适用于从宿主机或其他网络中访问虚拟机上的服务);
2.本地如何连接docker镜像:通常在运行容器时将其端口映射到宿主机的端口,如docker run -d -p 8080:80 <image_name>就是直接访问本地的8080端口即可访问到docker部署的服务。
所以直接用虚拟机的ens160 ip加上docker运行时的映射端口,就可以从本地访问到虚拟机中通过docker运行的服务。可以使用DBeaver直接连接pgvector数据库,也可用配置java工程访问pgvector数据库。
三、测试调用
上传本地知识
搜索本地知识
本地知识问答
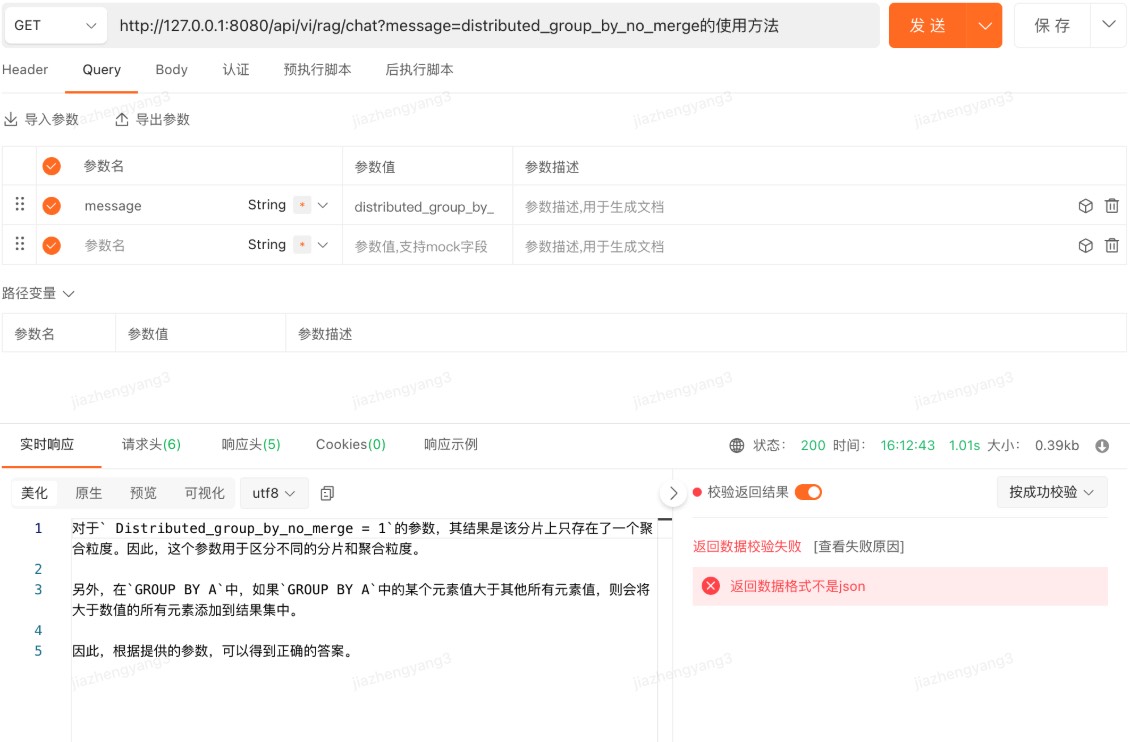
大模型直接问答