京东商智_基于ClickHouse预计算&智能物化预计算&日志解析&ck2hbase组件技术方案
一、背景
- 高QPS场景为满足查询性能需求,需要配置预计算策略,目前都是基于Hive表使用Spark引擎进行预计算,存在运算速度慢、浪费资源的问题,易导致关键看板SLA容易破线(eg:商智流量8点以后)、计算资源费用巨大(eg:商智流量3000元/天)。ClickHouse基于向量化执行引擎等优点运算速度快,且凌晨生产时段计算资源闲置,在一些场景下使用ClickHouse代替Spark作为预计算引擎对于用户来说收益巨大。
- 大量逻辑表直接基于ClickHouse物理表配置,基于明细数据的长周期查询性能差,目前需要用户自己手工维护ClickHouse的预计算加速,依赖人工且反应滞后,浪费研发人力资源。若提供基于ClickHouse明细的规则化预计算配置产品页面,可以大大节约用户的研发人力。
- 为了提高查询速度,提升查询性能,常用空间换时间的预计算策略来满足要求,我们已经提供了规则化的预计算加速策略配置页面,但是需要的输入规则项纷繁复杂,如指标、修饰、维度组合、聚合时间粒度、调度策略等,对用户带来了极大的理解和操作成本;且要求用户根据经验选择热点请求组合,存在误判造成资源浪费风险。为用户根据历史请求自动梳理热点请求组合,并基于历史信息自动对不满足查询速度要求的数据进行预计算加速供用户使用,再根据预计算数据请求命中率自动调整的一整套智能加速物化能力,能够帮助用户满足查询性能要求,减少用户配置成本,有效避免存储资源的浪费。
二、手动基于规则配置ClickHouse预计算技术方案
用户手动新增加速策略交互递进流程:

1.BE编辑与定义元数据
逻辑表定义


- 逻辑表类型:对于ClickHouse非中间态预计算和HBase预计算无变化,目标逻辑表类型logic_table_sub_type仍为PRE类型;对于ClickHouse中间态预计算,目标逻辑表类型logic_table_sub_type修改为DETAIL类型,表示基于该预计算目标表仍可进行聚合查询。
- 指标&指标修饰绑定关系:只为目标逻辑表添加用户指定的’指标@固化修饰’列表对应指标;将用户指定的固化修饰list存储到unify_drive_logic_table_metric_relation的inherent_speed_decorate_id_list字段中。
- 维度:只为目标逻辑表添加用户指定的维度组合中标准维度的并集。
- 修饰:预计算逻辑表无需添加修饰。
- 指标类型:对于ClickHouse非中间态预计算和HBase预计算无变化,目标逻辑表指标类型aggregation_type仍写死为SUM类型,aggregation_sub_type仍写死为空;对于ClickHouse中间态预计算,目标逻辑表指标类型aggregation_type保持与源逻辑表中的指标一致,对于非去重聚合方式aggregation_sub_type保持与源逻辑表中的指标一致,对于去重聚合方式aggregation_sub_type修改为*_Merge类型。
- 累计类型:全周期累计在所有维度路径中添加trend_type标准维度之后计算lvlcode,用于与分段累计进行区分。
加速策略定义
- 加速策略源逻辑表选择:若用户基于Hive物理表开始配置&已经配置了介质加速&配置ClickHouse预计算,那么该ClickHouse预计算加速策略的源逻辑表为介质加速的目标逻辑表;如果用户基于Hive物理表开始配置&未配置介质加速&配置ClickHouse预计算,那么该ClickHouse预计算加速策略的源逻辑表为Hive逻辑表。
- 加速策略发布状态:加速策略元数据表unify_drive_pre_calc_strategy添加一个状态标识字段,用于单独标识预发、线上、线上(编辑待发布)状态。
- 加速策略物化引擎类型:本次所述加速策略类型strategy_type皆为PRE_CALC,对于用户基于Hive物理表开始配置&未配置介质加速&配置ClickHouse预计算的场景,分别设置物化引擎为SPARK,或CLICKHOUSE。
- 加速策略单独存储指标修饰绑定关系:修改unify_drive_pre_calc_decorate_metric表主键为calc_strategy_business_id。
创建目标物理表
需要在新增时创建本地tmp、分布式tmp、本地线上、分布式线上四张表,并在加速策略新增字段编辑时add column。
- ClickHouse目标物理表:需要根据’指标@修饰’列表、维度组合并集创建ClickHouse目标物理表。
- ClickHouse跨天中间态目标物理表:需要额外添加tp、lvlCode字段,去重指标对应物理字段类型需要设置为AggregateFunction(*, )中间态类型。
- ClickHouse跨天非中间态目标物理表:需要额外添加tp、lvlCode两个字段,并将lvlCode作为主键的第一个字段。
- ClickHouse天以下中间态目标物理表:需要额外添加tp、lvlCode、业务时间time三个字段,去重指标对应物理字段类型需要设置为AggregateFunction(*, )中间态类型。
- ClickHouse天以下非中间态目标物理表:需要额外添加tp、lvlCode、业务时间time三个字段,并将lvlCode作为主键的第一个字段。
2.生产适配与存储协议升级
预计算逻辑表信息获取与生产工作流定义
- 任务纵向拆分:对于从Hive逻辑表到ClickHouse逻辑表的ck2ck预计算加速策略,新增一种工作流定义syncAndCalculate,拆分为互为父子依赖的两步骤,父任务为dataSyncTask介质加速步骤,子任务为calculateTask预计算步骤。
- 任务横向拆分:将以ClickHouse为目标引擎的任务都按照主备集群拆分为两个并发任务,并行执行。
预计算生产SQL适配
- 两步骤ClickHouse预计算生产SQL适配:对于从Hive逻辑表到ClickHouse逻辑表的ck2ck预计算加速策略,以Hive逻辑表ID、预计算DSL为入参获取到带有Hive方言的预计算SQL,决策引擎进行ClickHouse方言替换。
- 中间态存储SQL适配:对于中间态存储的加速策略,从SQL引擎获取到预计算SQL后,将去重函数*()替换为中间态去重函数*Merge()。
- ClickHouse预计算推数组件结果条数校验SQL拼接:将中间态存储的预计算SQL中的计算指标替换为count(1),与目标表中进行数据条数校验。
预计算推数组件开发
存储中间态本地聚合&非中间态分布式聚合:使用ck的max_execution_time和max_bytes_before_external_group_by参数避免预计算sql运行超时或超内存。火山引擎ELT技术实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106insert
into
sz.app_jdr_traffic_sz_lead_ord_cart_mvp_pre_calc_dis_d (dt,
shop,
last_src_channel_id_1,
last_src_channel_id_2,
last_src_channel_id_3,
tp,
lvl_code,
jdr_sch_traffic_intr_ord_ord_amt_shop_last_src_valid_snapshotIintr_flag,
jdr_sch_traffic_intr_ord_ord_amt_shop_last_src_valid_snapshotIintr_flag_spu,
jdr_sch_traffic_intr_ord_ord_amt_shop_last_src_valid_snapshotIintr_ord_sku,
jdr_sch_traffic_intr_ord_ord_amt_shop_last_src_valid_snapshotIintr_ord_spu,
jdr_sch_traffic_intr_ord_ord_qtty_shop_last_srcIintr_ord_sku,
jdr_sch_traffic_intr_ord_ord_qtty_shop_last_srcIintr_ord_spu,
jdr_sch_traffic_intr_ord_sku_piece_shop_last_src_deal_snapshotIintr_ord_sku,
jdr_sch_traffic_intr_ord_sku_piece_shop_last_src_deal_snapshotIintr_ord_spu,
jdr_sch_traffic_intr_ord_user_cnt_shop_last_src_valid_snapshotIintr_add_cart_spu,
jdr_sch_traffic_intr_ord_user_cnt_shop_last_src_valid_snapshotIintr_flag,
jdr_sch_traffic_intr_ord_user_cnt_shop_last_src_valid_snapshotIintr_ord_sku,
jdr_sch_traffic_intr_ord_user_cnt_shop_last_src_valid_snapshotIintr_ord_spu,
jdr_sch_traffic_intr_ord_user_cnt_shop_last_src_valid_snapshotIshop_user_180_newIintr_ord_sku,
jdr_sch_traffic_intr_ord_user_cnt_shop_last_src_valid_snapshotIshop_user_180_oldIintr_ord_sku,
jdr_sch_traffic_intr_ord_user_cnt_shop_last_src_valid_snapshotIshop_user_730_newIintr_ord_sku,
jdr_sch_traffic_intr_ord_user_cnt_shop_last_src_valid_snapshotIshop_user_730_oldIintr_ord_sku,
jdr_sch_traffic_intr_ord_user_cnt_shop_last_src_valid_snapshotIshop_user_newIintr_ord_sku,
jdr_sch_traffic_intr_ord_user_cnt_shop_last_src_valid_snapshotIshop_user_oldIintr_ord_sku,
jdr_sch_traffic_intr_ord_user_cnt_shop_last_src_valid_snapshotIsz_intr_add_cart,
jdr_sch_traffic_intr_ord_user_cnt_shop_last_src_valid_snapshotIsz_intr_follow)
SELECT
'2024-03-19' ckdt,
t.shop_id shop,
t.shop_sessn_src_zs_url_frst_catg_cd last_src_channel_id_1,
t.shop_sessn_src_zs_url_scnd_catg_cd last_src_channel_id_2,
t.shop_sessn_src_zs_url_thrd_catg_cd last_src_channel_id_3,
'BY_LAST_DAYS_30' tp,
'123456' lvl_code,
sum(if(t.is_vld_ord = 1, t.ord_amt, 0)) jdr_sch_traffic_intr_ord_ord_amt_shop_last_src_valid_snapshotIintr_flag,
sum(if(t.is_vld_ord_spu = 1, t.ord_amt, 0)) jdr_sch_traffic_intr_ord_ord_amt_shop_last_src_valid_snapshotIintr_flag_spu,
sum(if(t.is_ord = 1, t.ord_amt, 0)) jdr_sch_traffic_intr_ord_ord_amt_shop_last_src_valid_snapshotIintr_ord_sku,
sum(if(t.is_ord_spu = 1, t.ord_amt, 0)) jdr_sch_traffic_intr_ord_ord_amt_shop_last_src_valid_snapshotIintr_ord_spu,
uniq(if(t.is_ord = 1,
t.sale_ord_id,
null)) jdr_sch_traffic_intr_ord_ord_qtty_shop_last_srcIintr_ord_sku,
uniq(if(t.is_ord_spu = 1,
t.sale_ord_id,
null)) jdr_sch_traffic_intr_ord_ord_qtty_shop_last_srcIintr_ord_spu,
sum(if(t.is_ord = 1, t.sale_qty, 0)) jdr_sch_traffic_intr_ord_sku_piece_shop_last_src_deal_snapshotIintr_ord_sku,
sum(if(t.is_ord_spu = 1, t.sale_qty, 0)) jdr_sch_traffic_intr_ord_sku_piece_shop_last_src_deal_snapshotIintr_ord_spu,
uniq(if(t.is_add_cart_spu = 1,
t.usr_log_acct,
null)) jdr_sch_traffic_intr_ord_user_cnt_shop_last_src_valid_snapshotIintr_add_cart_spu,
uniq(if(t.is_vld_ord = 1,
t.usr_log_acct,
null)) jdr_sch_traffic_intr_ord_user_cnt_shop_last_src_valid_snapshotIintr_flag,
uniq(if(t.is_ord = 1,
t.usr_log_acct,
null)) jdr_sch_traffic_intr_ord_user_cnt_shop_last_src_valid_snapshotIintr_ord_sku,
uniq(if(t.is_ord_spu = 1,
t.usr_log_acct,
null)) jdr_sch_traffic_intr_ord_user_cnt_shop_last_src_valid_snapshotIintr_ord_spu,
uniq(if(t.is_180new_flag = 1
and t.is_ord = 1,
t.usr_log_acct,
null)) jdr_sch_traffic_intr_ord_user_cnt_shop_last_src_valid_snapshotIshop_user_180_newIintr_ord_sku,
uniq(if(t.is_180new_flag = 0
and t.is_ord = 1,
t.usr_log_acct,
null)) jdr_sch_traffic_intr_ord_user_cnt_shop_last_src_valid_snapshotIshop_user_180_oldIintr_ord_sku,
uniq(if(t.is_730new_flag = 1
and t.is_ord = 1,
t.usr_log_acct,
null)) jdr_sch_traffic_intr_ord_user_cnt_shop_last_src_valid_snapshotIshop_user_730_newIintr_ord_sku,
uniq(if(t.is_730new_flag = 0
and t.is_ord = 1,
t.usr_log_acct,
null)) jdr_sch_traffic_intr_ord_user_cnt_shop_last_src_valid_snapshotIshop_user_730_oldIintr_ord_sku,
uniq(if(t.is_allnew_flag = 1
and t.is_ord = 1,
t.usr_log_acct,
null)) jdr_sch_traffic_intr_ord_user_cnt_shop_last_src_valid_snapshotIshop_user_newIintr_ord_sku,
uniq(if(t.is_allnew_flag = 0
and t.is_ord = 1,
t.usr_log_acct,
null)) jdr_sch_traffic_intr_ord_user_cnt_shop_last_src_valid_snapshotIshop_user_oldIintr_ord_sku,
uniq(if(t.is_add_cart = 1,
t.usr_log_acct,
null)) jdr_sch_traffic_intr_ord_user_cnt_shop_last_src_valid_snapshotIsz_intr_add_cart,
uniq(if(t.is_follow = 1,
t.usr_log_acct,
null)) jdr_sch_traffic_intr_ord_user_cnt_shop_last_src_valid_snapshotIsz_intr_follow
FROM
sz.app_jdr_traffic_sz_lead_ord_cart_mvp_i_d_d_thrd_agg_d t
WHERE
(
(t.dt >= '2024-02-19')
AND (t.dt <= '2024-03-19')
)
GROUP BY
t.shop_id,
t.shop_sessn_src_zs_url_frst_catg_cd,
t.shop_sessn_src_zs_url_scnd_catg_cd,
t.shop_sessn_src_zs_url_thrd_catg_cd
settings max_execution_time = 600,
max_memory_usage = 60000000000,
max_bytes_before_external_group_by = 30000000000
可用时间回写
- 根据生产任务回写可用时间:当前元数据中心逻辑表可用时间粒度为logic_table_id,一个加速策略对应一张目标逻辑表,则一个加速策略需要等待所有时间策略完成之后才可更新逻辑表可用时间。
- 可用时间随配置ttl裁剪:将配置ttl作为数据生命周期,引擎中数据到期时需裁剪对应逻辑数据可用时间,需要考虑同比场景。
加速策略依赖可配置为加速策略
- 添加加速策略依赖类型。
三、智能物化技术方案

1.热点日志解析
过滤与打平:过滤出请求定义驱动服务clickhouse引擎生产环境离线数据的请求,并将请求中的指标、维度、属性、聚合字段、排序字段等半结构化数据进行结构化解析。
过滤不符合加速条件的请求:非聚合仅过滤维度的过滤维值为单值则等效于该维度同时是聚合维度和过滤维度,过滤维度与聚合维度完全匹配即为点查,聚合维度大于过滤维度即位榜单查询。只有上述两种请求才应该路由到完全预计算数据上去,对这些请求按上述种类进行分类。
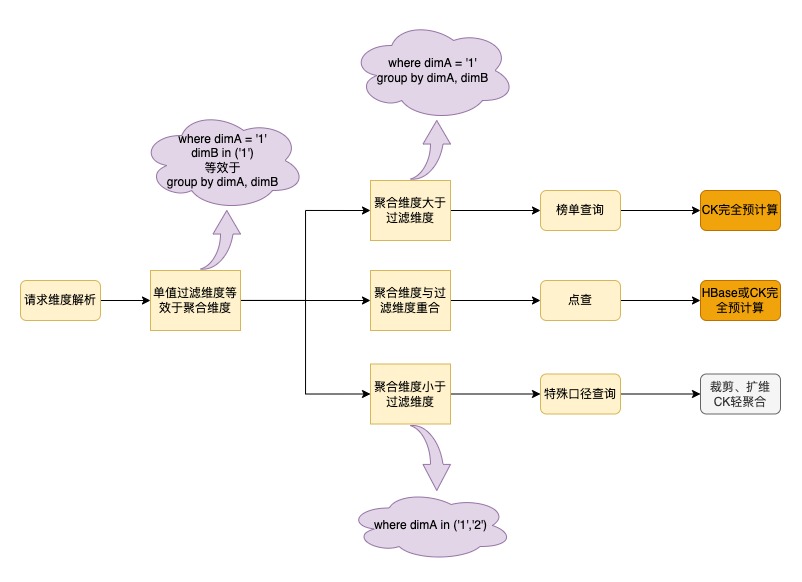
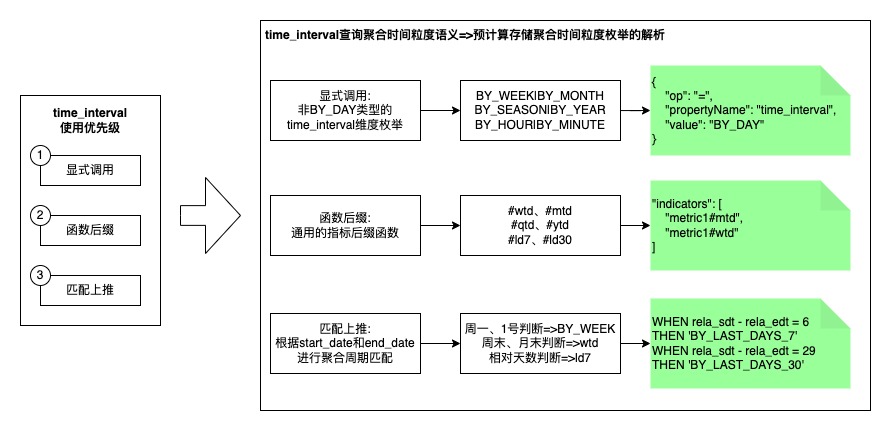
请求聚合周期解析:使用提取聚合时间函数、显示time_interval、开始结束时间匹配三种方法获取请求聚合时间粒度,并将为获取到时间粒度的请求过滤掉。
请求耗时聚合解析:以指标列表+聚合维度列表+聚合时间粒度为基本请求单位,对请求耗时进行聚合分析。
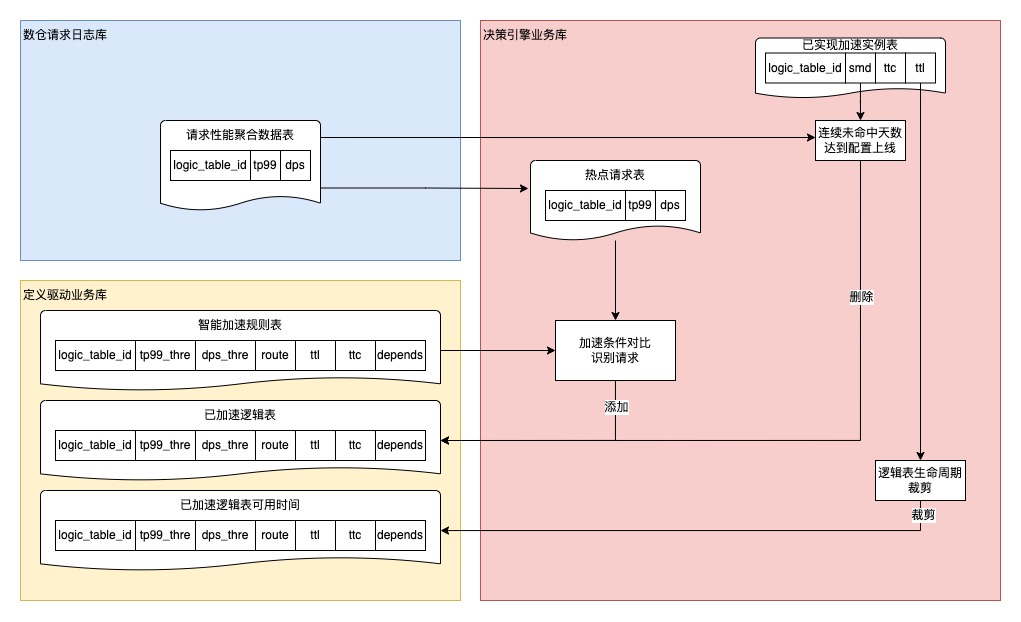
出库和按热点条件配置进行热点判断:将请求性能数据进行聚合并出库到决策引擎MYSQL表,按用户在智能加速页面配置的逻辑表请求热点条件对解析日志得到的基本请求单元进行耗时比较与热点判断。



具体加工sql见下一节。
2.智能加速策略自动插入
- 指标清洗:依赖元数据中心拆分指标和修饰,修正逻辑表与指标的绑定关系,得到正确的需要加速的动态修饰指标+维度组合+逻辑表。
- 预发环境逻辑表状态判断:只有逻辑表处于线上状态时才可以添加智能物化加速策略,否则会在智能物化加速策略发布时,把预发的用户改动直接带到线上去。
- 加速策略变更幂等:以指标列表+维度组合+聚合周期为判重标准,判断增删改操作。
- 插入加速策略:构建新增加速策略相关bean,调用加速策略新增接口,插入需要进行预计算的热点动态修饰与指标绑定关系到预发环境,然后调用源逻辑表的发布接口发布到线上。
3.可用时间回写
智能加速可用时间回写方案与规则配置加速策略中的可用时间回写方案相同。
4.目标表生命周期裁剪
5.低可用率策略清除
智能加速目标逻辑表请求命中天数更新:根据日志判断
6.其他依赖功能
加速策略时间策略依赖类型扩充:依赖可以是bdp任务,也可以是定义驱动的的时间策略。
四、日志解析
1.入参case
请求调用成功(doFetchBizData invoke.)params案例:
1 | { |
easydata调用成功(EasyDataExternalService success executeSql)params案例:
1 | { |
2.打平与过滤
1 | INSERT OVERWRITE TABLE """ + dest_table_name + """ PARTITION (dt='""" + ht.data_day_str + """') |
3.点查、榜单查询、不可预计算查询识别与分类
1 | INSERT OVERWRITE TABLE """ + dest_table_name + """ PARTITION (dt='""" + ht.data_day_str + """') |
4.请求聚合周期解析
1 | WITH |
5.请求耗时聚合计算
1 | INSERT OVERWRITE TABLE """ + dest_table_name + """ PARTITION (dt='""" + ht.data_day_str + """') |
五、ck2hbase组件架构
1.背景
1)当前预计算任务主要基于spark集群进行数据计算再推到hbase等kv数据库,spark离线计算集群按资源使用率进行计费,费用高昂;且在分区数据量级1亿场景下,spark引擎计算效率不如ck引擎,考虑通过ck凌晨生产时段进行预计算加工既可以节约成本,又可以提高时效;
2)当前定义驱动大量用户直接基于ck表新建逻辑表,缺乏从hive开始进行预计算的加工链路,需要ck2hbase的能力支持才能进行预计算加速结果到kv数据库。
2.主要难点
单节点计算命令提交主要存在两个问题:
1)计算超时,当数据量和计算量较大时,单条命令执行时间较长,一般平台设置即席查询超限时间20s,沟通后最多提升到600s,对大批量有聚合计算的查询仍有瓶颈;
2)本地节点内存超限,当数据量较大时,从远程节点返回给本地节点进行聚合计算的数据量也会很大,易导致内存超限。
其实也可以借鉴第二节中的ck2ck使用ck的执行时间和内存溢出参数。
3.技术方案
分两步查询:
1)选取维度枚举值最多的标准维度,查询出所有维值列表,将这些维值按节点散列;
2)按照散列每个节点进行其中一部分维度数据的聚合计算。这种分散计算的方式在本业务场景下并不会降低集群整体的计算压力,主要目的是将运算时间和本地聚合运算所需内存进行分散,避免超过相应安全限制。
整体加工流程如下:

4.执行结果
ck2hbase组件开发完毕,对于全渠道流量场景的180亿底表数据按shop_id、first_source维度组合进行预计算,生成4千万结果数据写入hbase,ck引擎和spark引擎对比结果如下:任务运行时间9min,相同业务场景下基于hive使用spark引擎进行预计算任务运行时间33min。
| ck2hbase | spark2hbase | |
|---|---|---|
| 使用时间 | 9min | 33min |
| 节点数量 | 120 | 1500 |
| 资源收费 | 免费 | 按使用核数*时间计费 |
| 数据准确度 | uniq模糊去重 | 精确去重 |