数据开发之离线计算_MapReduce计算过程详解
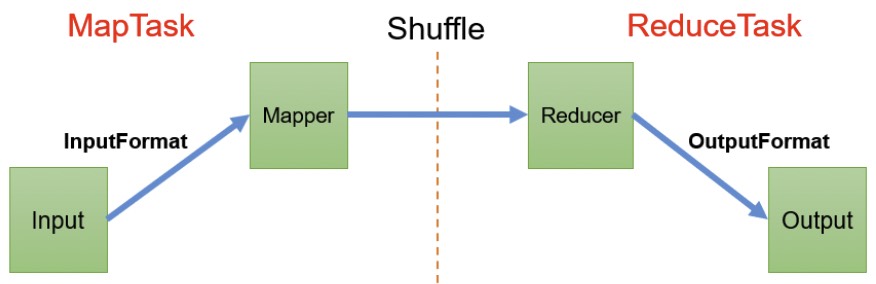
1.MapReduce流程总结
1.1 流程图
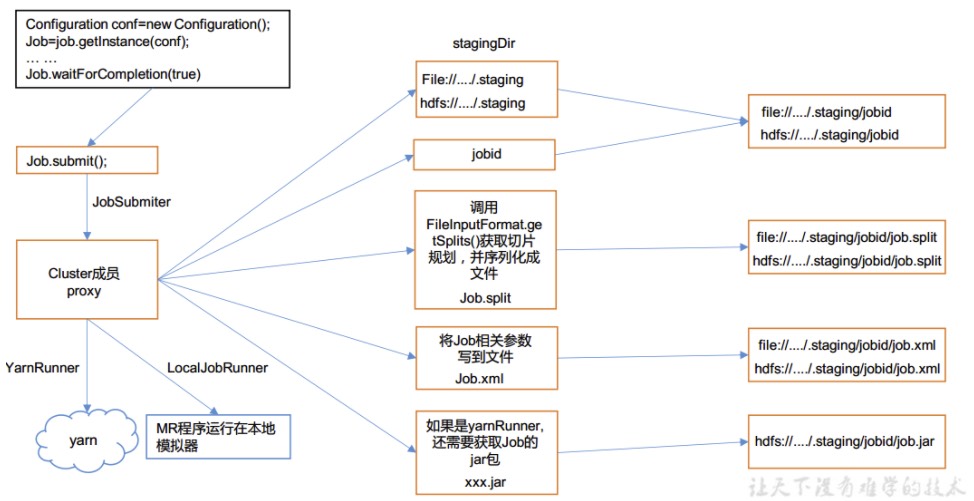
1.2 Job创建与提交
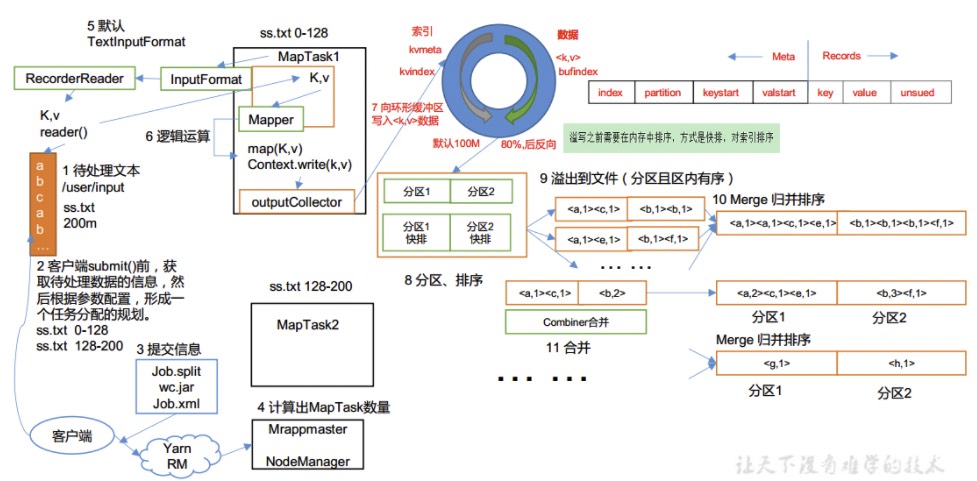
job创建和提交步骤中,首先需要创建yarn计算集群的代理对象,然后创建存储任务文件的staging路径,将split切片信息、配置文件、jar包保存到该路径,然后将该路径中的文件通过代理对象提交给yarn集群去运行。
MapTask的并行度,也就是map任务的个数取决于InputFormat输入对象的getSplits()切片信息,不同类型的InputFormat实现类进行切片的规则也不同。比如普通的TEXT文件默认可以直接根据数据大小进行切片,将一个文件切成多个切片;使用了ZSTD格式压缩的TEXT文件则默认一个文件就是一个切片;hbase的hfile文件也是默认一个hfile文件就是一个切片;也可以使用CombineTextInputFormat将多个小文件规划到同一个切片中。
注意hdfs系统的Block数据块与数据切片没有关系,Block是hdfs在物理机上对数据的分块,也是hdfs保存副本的基本单元;数据切片则是mapreduce程序对输入数据在逻辑上的划分,并不会涉及到物理存储上的划分。
hadoop fsck命令可用于查看hdfs文件或目录的健康状况,包括存储的block个数。
hadoop fsck hdfs://ns22017/user/ads_sz_load/hfile_convert/origin
1.3 Shuffle过程细节要点
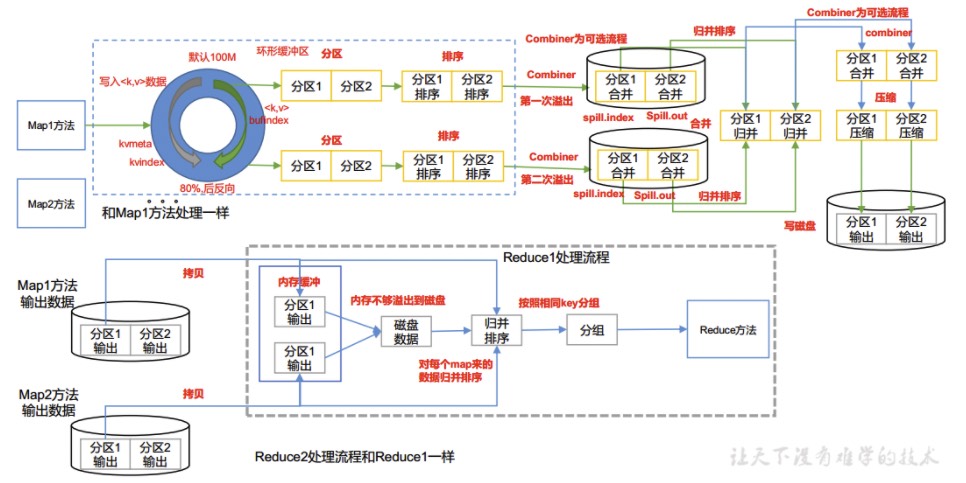
- Shuffle过程是1.1节流程图中的第7步到第16步;
- 环形内存缓冲区默认大小为100M,当环形内存缓冲区中的存储默认达到80%时开始反向溢出写到磁盘,每一个MapTask会有一个环形内存缓冲区,所有map计算结束之后,多个溢出文件会合并成大的溢出文件;
- 数据在环形内存缓冲区中溢出写之前,在不同分区内按照字典序进行快速排序,这些分区是按照reduce来确定的,同一个分区中的数据后续要交给同一个ReduceTask,所有有多少个ReduceTask就会有多少个分区;
- 溢出写排序和合并归并排序过程中都要掉用Partitioner的getPartition()进行分区,从而在分区内对key进行排序;
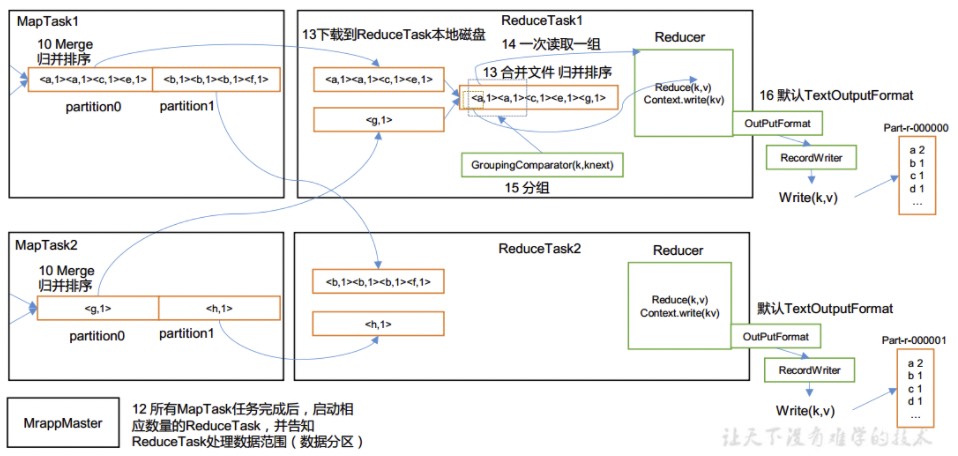
- ReduceTask根据自己的分区号,去各个MapTask机器上取相应的结果分区数据,然后将这些来自不同MapTask机器上的数据再次进行合并归并排序,得到一个大文件作为reduce计算的输入文件,Shuffle的过程到这里也就结束了。
- 可以自定义partition分区方式和相应的reduce数量,但是一定要满足partition分区数量与reduce数量的对应关系。
1.4 Combiner
combine是一个可选步骤,在MapTask阶段可以选择进行一轮combine操作,如上图步骤11,用于降低网络传输的数据大小。
Combiner的本质就是在每个MapTask中提前进行一次局部的reduce,这次reduce只处理该map输出的数据。
Combiner类必须继承Reducer类,可以重写reduce方法实现不同的计算逻辑,也可以单纯的直接复用原reduce计算逻辑,然后使用job.setCombinerClass(Combiner.class)方法添加Combiner类。
注意如果设置job.setNumReduceTasks(0)那么combine也不会执行了,因为reduce不存在了。
2.spill和merge
存储map计算结果的环形内存缓冲区是通过三个环形数组构成的,分别是kvoffsets,kvindices,kvbuffer。
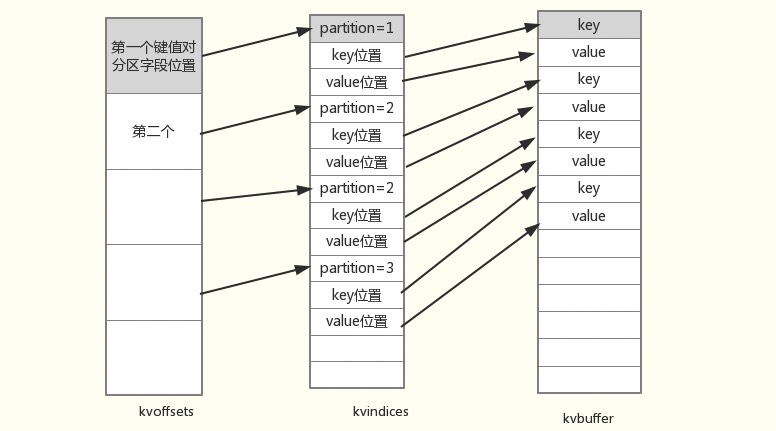
kvoffsets和kvindices都是int[]型数组,而kvbuffer是byte[]型数组。kvoffset数组中的一个元素存储一个数据键值对在kvindices数组中的索引,而kvindices数组中的连续三个元素分别存储一个数据键值对的分区号和在kvbuffer数组中的键值索引。
spill前的分区快排事实上只是交换了kvoffsets数组中值的位置。
默认环形内存缓冲区存储达到80%时spill,也可以自己调整大小。但是最好不要设置成100%时spill,不然会导致spill时不能写入数据。
一个map一般会产生很多的spill文件,在MapTask正常结束之前会被merge合并成一个大的out文件和index文件。然后这些大out文件在reduce执行完毕,整个job完成之后才会被通知删除。这些中间文件都是存储在hadoop.tmp.dir临时文件夹中。
3.MapReduce的性能调优
3.1数据输入调优
当小文件过多时会造成产生大量map任务,导致map任务的装载时间反而拖累整体速度,这时可以采用CombineTextInputFormat作为输入。
3.2 Map调优
减少spill次数:通过conf.set()方法覆写mapred-default.xml文件中的mapreduce.task.io.sort.mb参数和mapreduce.map.sort.spill.percent参数,调大内存缓冲区大小和spill溢写阈值。
减少merge次数:通过conf.set()方法覆写mapred-default.xml文件中的mapreduce.task.io.sort.factor参数,调大每次merge的文件数目。
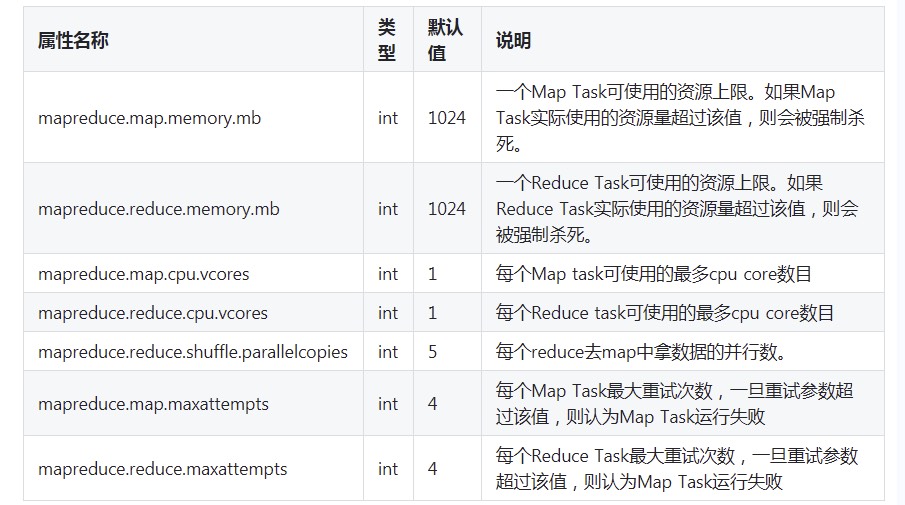
3.3其他调优属性
1 | //设置map进程的物理内存使用上限。 |