HBase表数据倾斜治理_HBase行数计算
1.主备一致性验证
数据库最常见的主备一致性验证主要有两个方面:一个是数据准确性验证,这方面主要通过同一个查询语句得到的查询结果是否相同来验证;另一个是数据量的一致性验证,这方面主要通过行数计算来验证,比如全量数据条数、某个时间段内数据条数。如京东当前的clickhouse、hbase、durid数据库都是采用这种方式来验证主备一致性。
2.使用Filter来实现HBase行数计算
2.1基本原理
hbase行数计算的本质就是使用scan扫描全表数据来进行行数统计,那么hbase行数计算的优化本质就是提升scan效率。
2.2优化策略
本文采用了从3个方面来进行优化:
- 通过Scan.addFamily()和scan.addColumn()来实现仅扫描单列簇或单列,减少扫描时间。
- 通过Scan.setTimeRange()来实现扫描指定时间段内存入数据,可以实现不扫描全表,而仅计算某一天存入的数据条数。
- 通过FirstKeyOnlyFilter过滤器来实现仅扫描同一个rowkey的第一个cell,减少扫描时间。
之前就学习和总结过scan的流程,如下图所示:
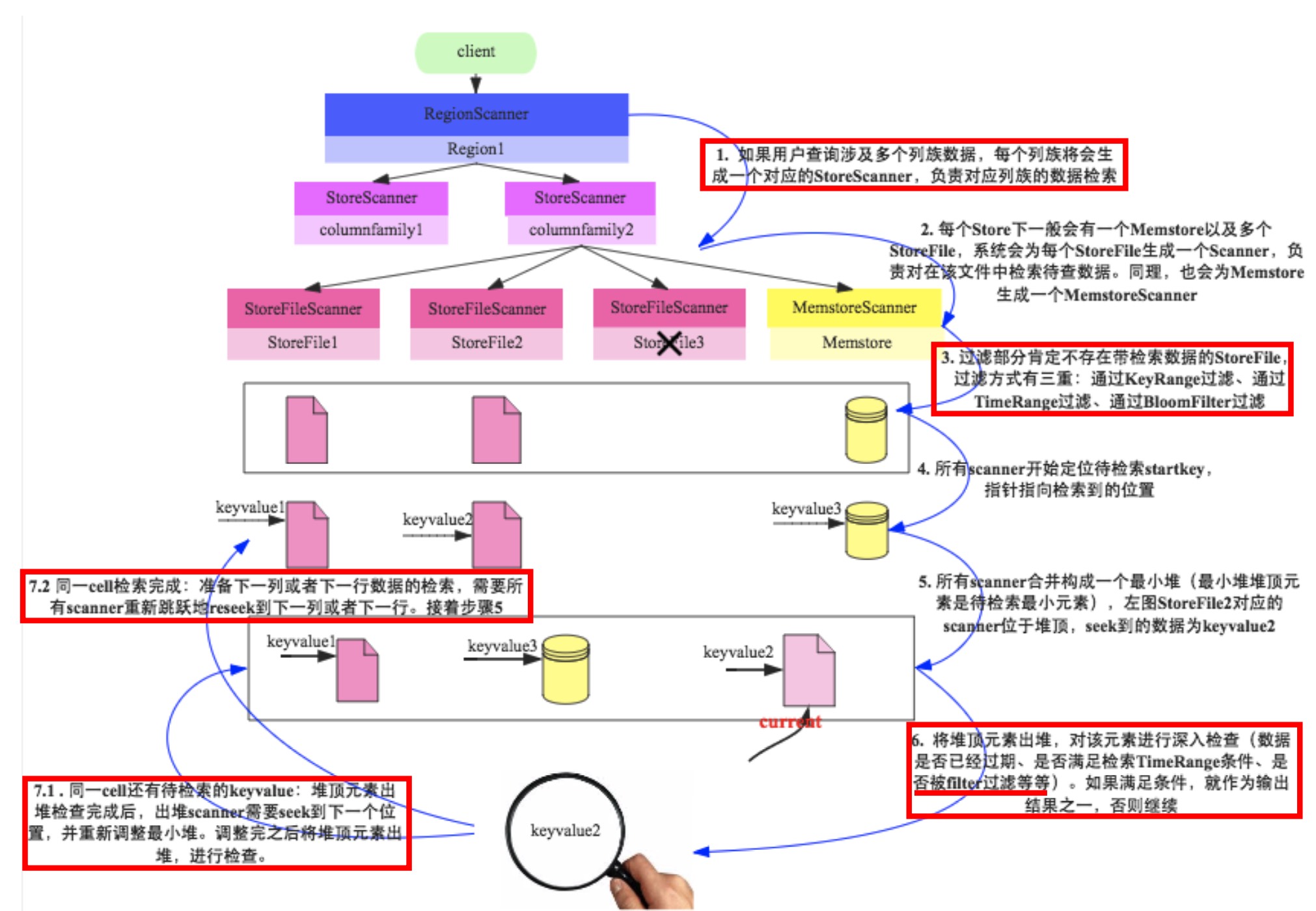
上述的列簇的扫描过滤是在步骤1当中,只会对指定的列簇生成StoreScanner进行数据检索;
时间戳扫描过滤是在步骤3和步骤6当中,步骤3当中是直接过滤掉根本没有该时间戳数据的文件,步骤6当中则是对正在扫描的cell进行时间戳比较过滤;
FirstKeyOnlyFilter过滤器过滤是在步骤7.2当中,完成了一个rowkey的一个cell扫描之后就直接准备下一行数据的检索,而不进行下一列数据的检索。
2.3 HBase时间戳与TTL
每个cell当中保存的版本号其实就是该cell插入时存入的时间戳timestamp字段,单位为毫秒。如果存入数据时添加了该字段值则为设置值,如果没有添加则默认该字段值为数据插入的当前时间戳。
比如一个cell数据实例:
rowkey=\x00\x00\x00\x00\x00\x00\x00\x01\x00\x00\x00\x01\x00\x00\x00\x00\x00\x03\x15\xDF\x00\x00\x00\x03\x00\x00\x00\x00\x00\x00\x00\x02\x00\x00\x00\x00\x00\x00\x07\xD2\x00\x00\x00\x00\x00\x1E\x8CT\x1C\xFC\xCF\x05, column=d:AvgDepthSingle , timestamp=1656880971313 , value= ?�
hbase有一个TTL(time to live)数据有效期标识,单位是毫秒。TTL是一个表级别的设置,也就是一整张表中所有数据的TTL都是相同的。
那么TTL生效的本质就是利用数据的时间戳与TTL进行比较,比如一张表的TTL为86400000,也就是一天,那么进行数据查询或者数据整理是,判断该数据能否被返回或者是否被清理的标准就是当前系统时间currentMilliseconds-timestamp>86400000,如果满足该条件则该cell数据不能被返回或被清理。
hbase当中的update操作本质就是添加一条相同rowkey而不同timestamp的数据;delete操作本质就是对小于当前currentMilliseconds的cell中timestamp最大的那个cell打上删除标识;scan操作本质就是获取小于当前currentMilliseconds的cell中timestamp最大的那个cell。也是就是说add、update、delete、scan操作实际上都是带时间戳的。
那么有一种情况就是在进行增删改查时自定义timestamp。尤其是在add时借助自定义timestamp可以实现个性化的TTL。但是要小心使用,如果添加数据时使用了自定义timestamp,那么在update、delete、scan时也要考虑是否使用自定义timestamp才能达到目的。
2.4应用实例
2.4.1 MapReduce实现scan扫描与行数计算
1 | public class RowCounterTest { |
- MapReduce一般都是通过在Mapper类中创建内部枚举类来实现计数,具体实现方式见上述代码。
2.4.2 命令行语句
扫描列簇指定d,扫描时间范围指定为全表:
1 | hadoop jar RowCounterTest-1.0-SNAPSHOT.jar hb_ibd:HB_IBD_UNBOUNDER_TRADE_BRAND d_null 0_0 |
扫描列簇指定d,扫描时间范围指定为2022-07-09全天:
1 | hadoop jar RowCounterTest-1.0-SNAPSHOT.jar hb_ibd:HB_IBD_UNBOUNDER_TRADE_BRAND d_null 1657296001000_1657382399000 |
全表行数计算结果日志:
1 | [2022-07-10T16:32:35.688+08:00] [INFO] hadoop.mapreduce.Job.monitorAndPrintJob(Job.java 1417) [main] : Job job_8766029101801_70452735 completed successfully |
2022-07-09全天行数计算结果日志:
1 | [2022-07-10T16:28:19.261+08:00] [INFO] hadoop.mapreduce.Job.monitorAndPrintJob(Job.java 1417) [main] : Job job_8766029101801_70452892 completed successfully |
3.使用Coprocessor来实现HBase行数计算
相比于使用过滤器来进行scan提效,实际上使用协处理器来进行scan提效的效果要更好。
hbase本身已经支持了包含相关简单聚合函数的协处理器org.apache.hadoop.hbase.coprocessor.AggregateImplementation,一般来说直接在代码中调用相关hbase api对表进行disable,然后注册该coprocessor再enable即可。但是京东的hbase管理部门对表的disable操作进行了限制,一般用户无权限对线上表进行该操作,也就无法自行对表进行协处理器注册操作。
应用实例:
1 | public class AgreementTest { |
命令行语句:
1 | hadoop jar AgreementTest-1.0-SNAPSHOT.jar |
全表行数计算无权限报错日志:
1 | [2022-08-07T17:16:50.653+08:00] [INFO] hbase.client.HBaseAdmin.call(HBaseAdmin.java 1268) [main] : Started disable of hb_ibd:HB_IBD_PRO_ANALYSIS_FLOW_RECENT_NEW |