数据开发之离线计算_Hdfs&Yarn&MapReuduce架构关系与MapReduce推测任务原理
1.Hdfs架构&Yarn架构&MapReuduce组件之间的对应关系
1.1 Hdfs架构
一个hdfs集群包含一个namenode,用来管理文件系统的命名空间,以及调节客户端对文件的访问。一个hdfs集群还包括多个datanode,用来存储数据。
1.2 Yarn架构
Yarn是一个通用分布式资源管理系统和调度平台,为上层计算应用程序(mapreduce、spark等)提供统一的资源管理和调度,为这些程序提供运算所需的资源(内存、CPU)。yarn不关心你干什么,只关心你要资源,在有的情况下给你,用完之后还给我。
hadoop能有今天这个地位,yarn功不可没,因为有了yarn,更多计算框架可以接入hdfs中,而不单单是mapreduce,使得这些计算框架能专注于计算性能的提升。

通常yarn集群和hdfs集群是一起搭建的,一个yarn集群包含一个resourcemanager,用来接受用户的作业提交,并决定系统中所有应用程序之间资源分配的最终权限。一个yarn集群还包括多个nodemanager,一台机器上一个,负责管理本计算机上的计算资源。通常namenode与resourcemanager是部署在同一台机器上的,datanode与nodemanager是部署在同一台机器上的。
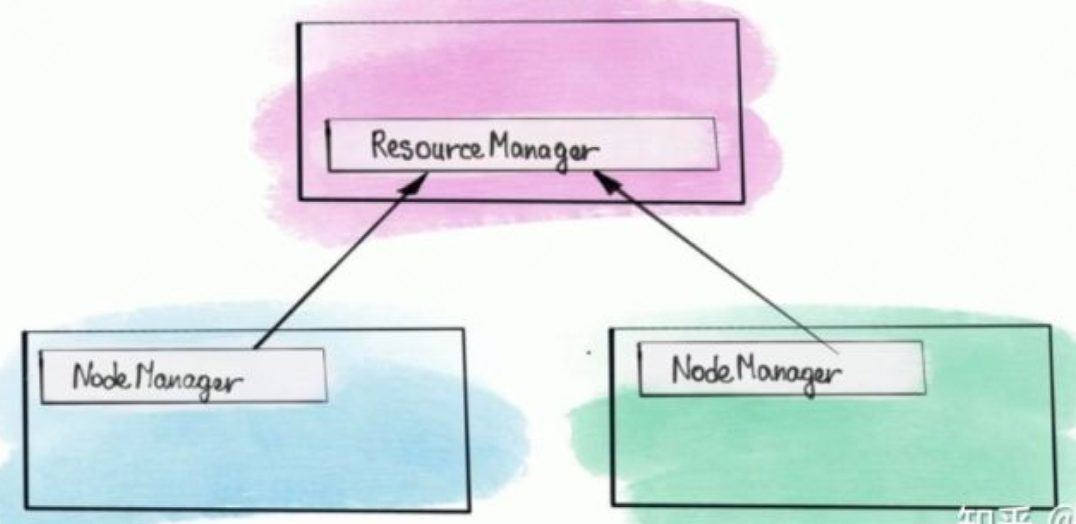
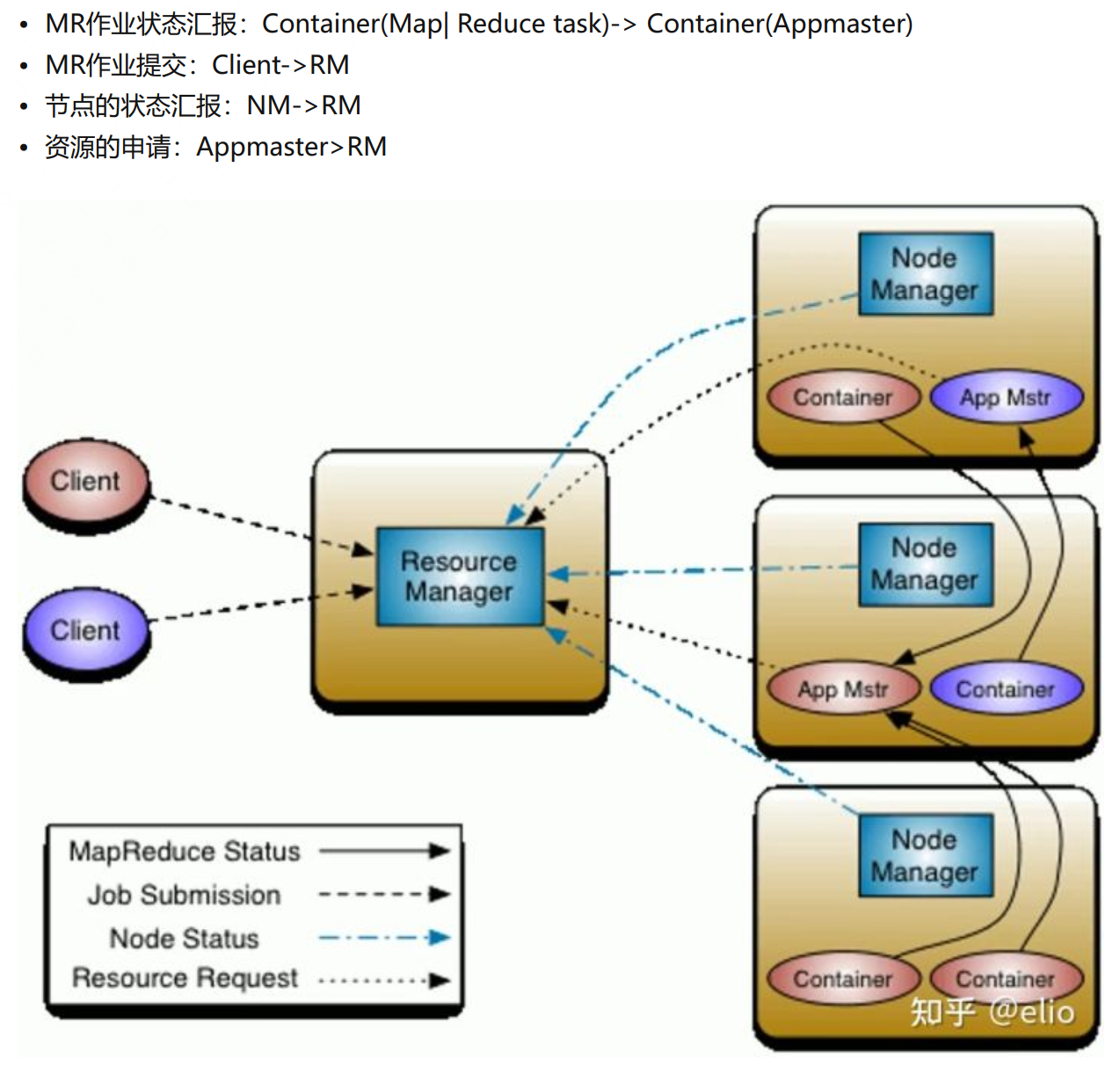
yarn中除了RM和NM还有一个很重要的组件就是applicationmaster,AM是一个动态组件,当用户向yarn提交计算任务应用程序时,RM首先会为该应用程序分配第一个container,并在该container中启动AM,作为该应用程序的总调度器。也就是说AM是一个运行在某一台NM服务器上的动态程序,提交了多少个计算任务(mapreduce、spark等)yarn集群上就有多少个AM,没有计算任务yarn集群上就没有AM。
AM的主要作用有:1.通过RPC协议向RM申请和领取计算资源;2.通过RPC协议获取计算任务的子任务状态和进度,对子任务执行启动、重启、杀死、获取参数等命令。
一个yarn集群运行两个mapreduce计算任务的示意图如下,其中yarn集群是以container容器的形式为计算任务分配计算资源的:
1.3 MapReduce组件
在hadoop1.x软件架构中,有两大核心模块mapreduce和hdfs,mapreduce计算引擎与hdfs集群共同部署,hdfs集群负责数据存储,mapreduce引擎负责计算和计算调度。
在hadoop2.x软件架构中,考虑到mapreduce引擎同时处理计算和资源调度,耦合性较大,增加了yarn资源调度框架,共同组成三大核心模块。mapreduce计算引擎、yarn集群、hdfs集群共同部署,hdfs负责存储,yarn负责资源调度,mapreduce负责计算。
mapreduce引擎的三个核心组件为jobtracker、tasktracker、taskscheduler,一个hadoop集群包含一个jobtracker、一个taskscheduler和多个taskscheduler。通常namenode与jobtracker是部署在同一台机器上的,datanode与tasktracker是部署在同一台机器上的,也就是说hadoop2.x集群中的namenode、resourcemanager、jobtracker三者数量相同,datanode、nodemanager、taskscheduler三者数量相同。
当用户将一个计算任务提交给jobtracker后,jobtracker会为这个job生成一个JobInProgress(JIP)实例来记录该job的所有状态信息,并将一个拆分为多个task,并未每一个task生成一个TaskInProgress(TIP)实例来记录该task的所有状态信息。也就是说集群上总共只有一个jobtracker节点,集群上有多少个计算任务就有多少个JIP实例。
为了更好的容错性,hadoop引入了TaskAttempt(TA)来表示每一个task的执行实例,TIP与TA的关系可以理解为程序与进程的关系,一个TIP可以对应多个TA。每启动一个执行该Task的实例,就会多一个TA,最终不管哪个TA先执行完,则认为该Task执行完毕,杀死该Task的其他TA。
一般是一台机器上部署一个tasktracker,定时向jobtracker通过心跳信息汇报节点的资源信息和任务运行状态信息。同时tasktracker在节点有空余资源时会向jobtracker请求新的任务,jobtracker收到请求后会借助taskscheduler为该节点分配任务队列。一个tasktracker可以同时运行多个不同job、不同task的TA。
2.MapReduce推测任务原理
2.1 推测任务
常规情况下一个TIP只启动一个TA,但是如果jobtracker发现某个job的某个task的进度明显慢于该job其他并行task的进度,那么jobtracker会启动一个推测TA作为备份执行实例。最后无论那个执行实例先执行完,就代表该task执行完,同时kill掉其他执行实例。
2.2 Progress的更新
当某个tasktracker将其负责的所有TA的状态信息通过心跳同步给jobtracker之后,jobtracker会更新每个TIP的状态信息。在mapreduce中,每一个TA都有一个taskstatus类的实例来维护其状态,每一个TIP就是维护一个taskstatus实例列表。那么一个TIP的执行进度信息progress就选择它的所有TA中进度最快的那个来表示。
3.MapReduce推测任务执行问题处理实例
3.1 背景
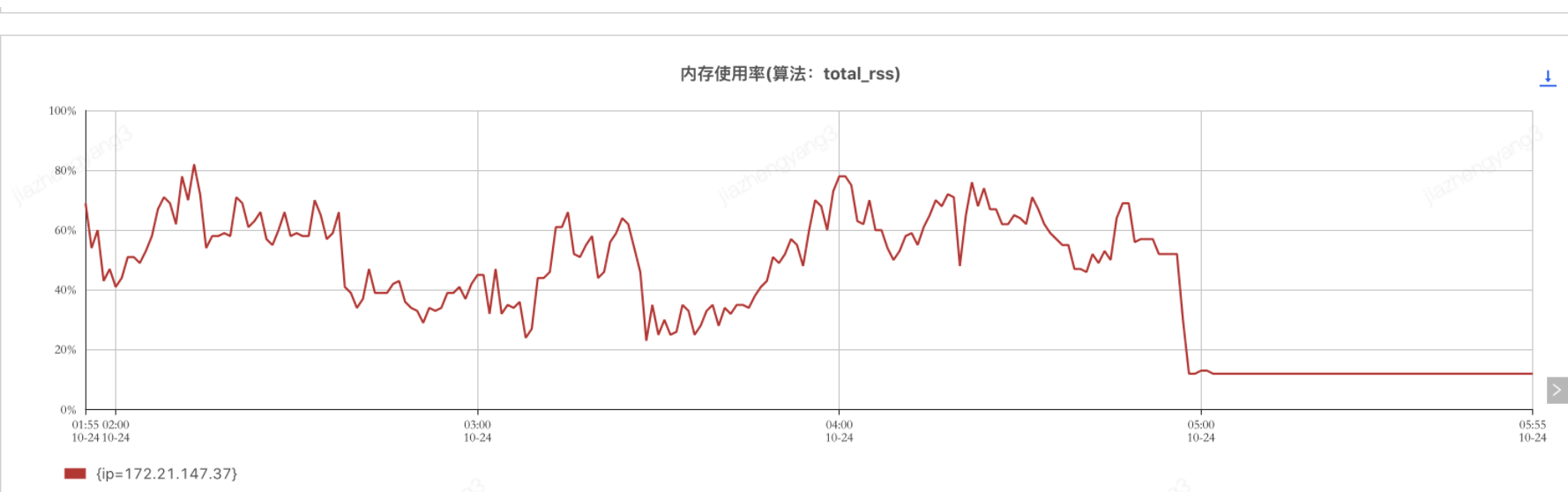
夜间mr生产任务执行进度reduce阶段达到100%了,且mapreduce任务监控界面上上排也显示了map和reduce任务全部执行完毕,但是任务一直不结束推出,且从mapreduce任务监控界面上看下排也可以看到有两个reduce任务TA一直处于running状态,如下图所示:
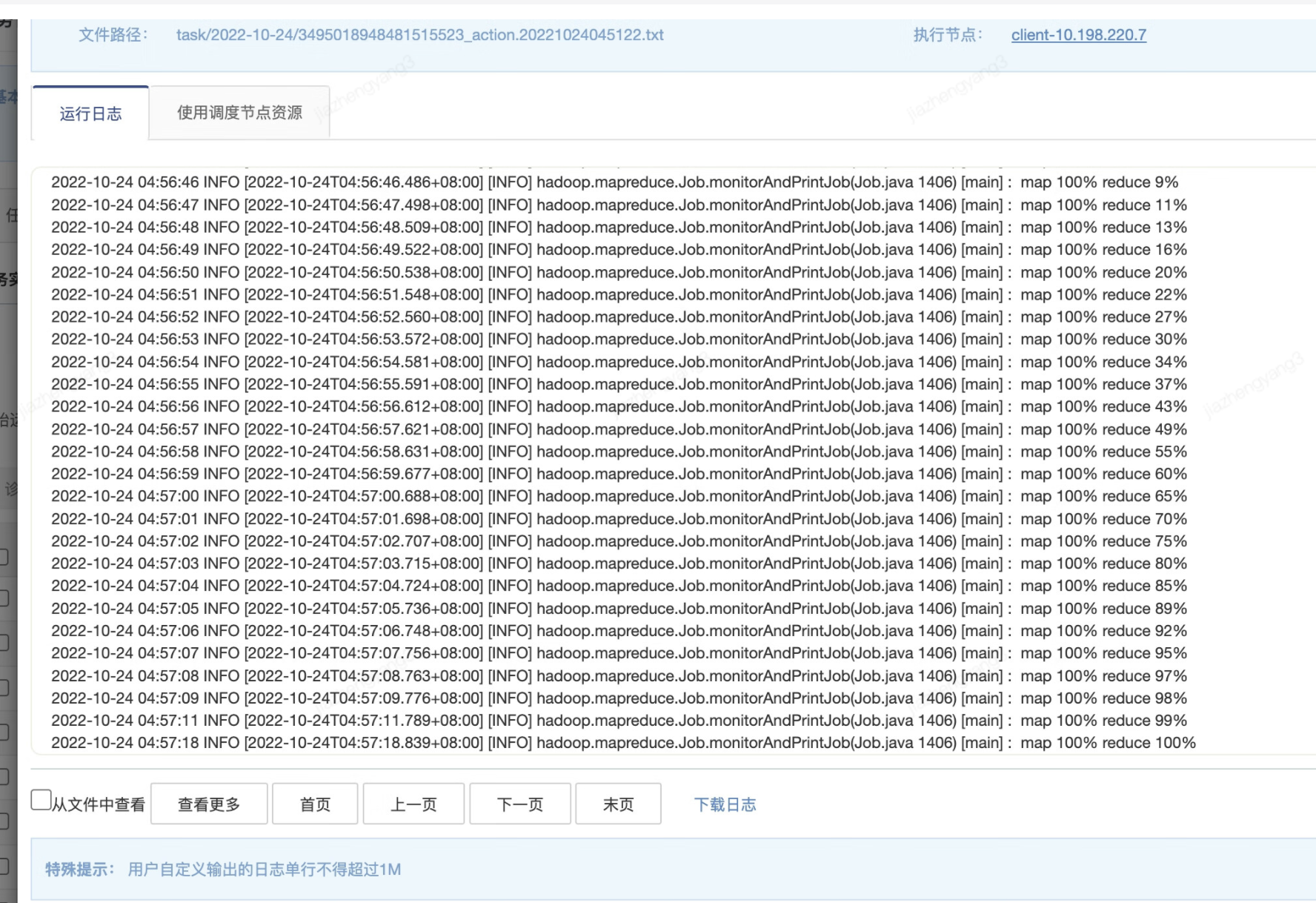
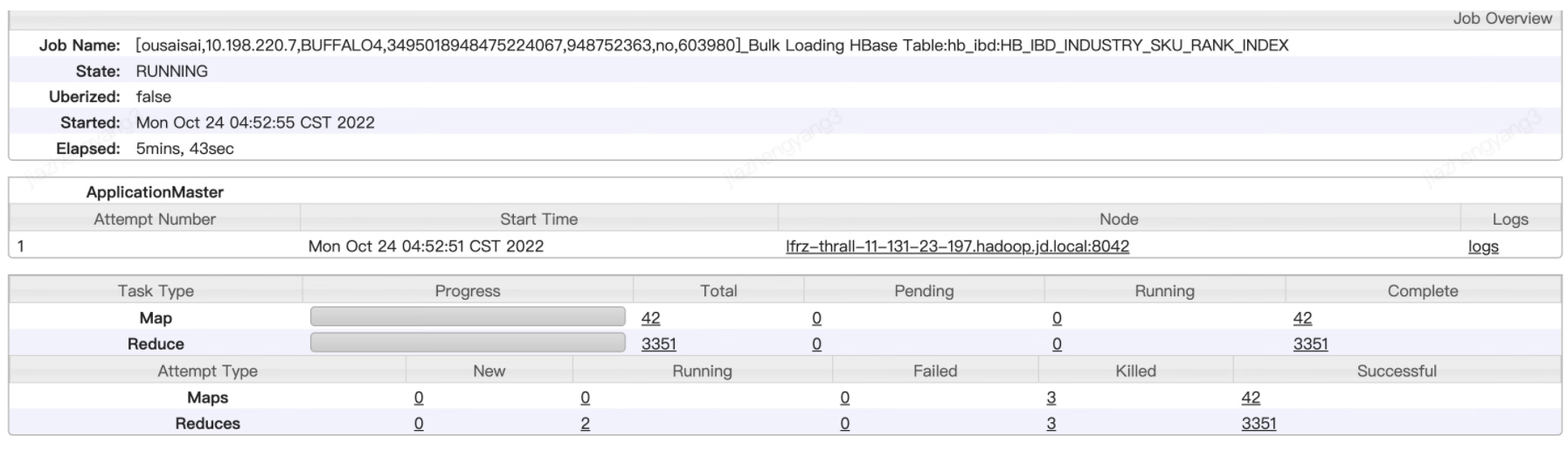
点开对应的reduce任务TA监控界面可以看到,TA的progress显示了100%进度,note中也显示了本任务的其他TA执行成功了,但是state就是一直卡在running阶段,如下图所示:
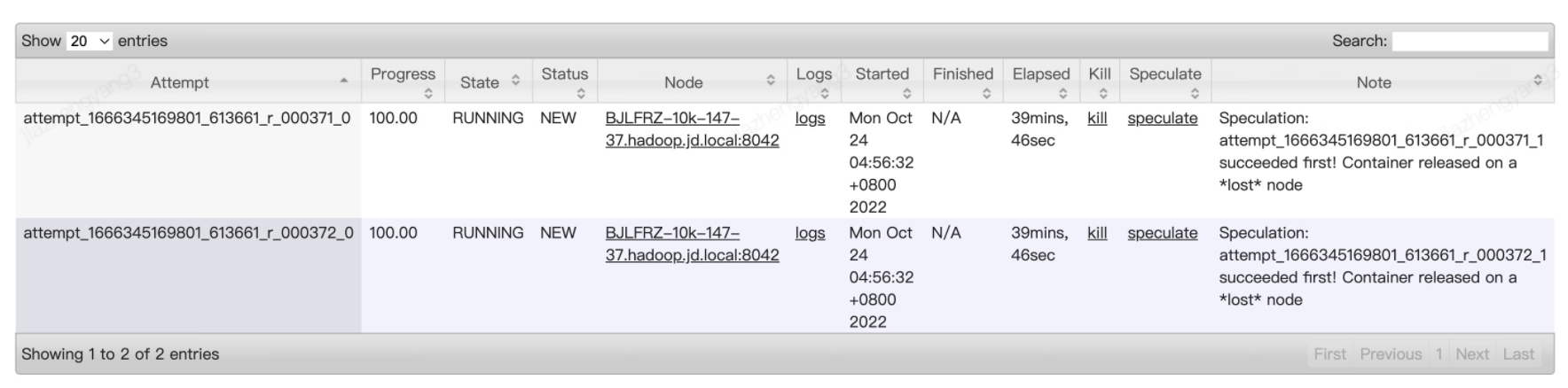
3.2 问题解决
直接手动点击上述两个卡住的TA监控界面上的kill按钮,手动杀死这两个TA,该mr任务就顺利的正常结束了,如下图所示:
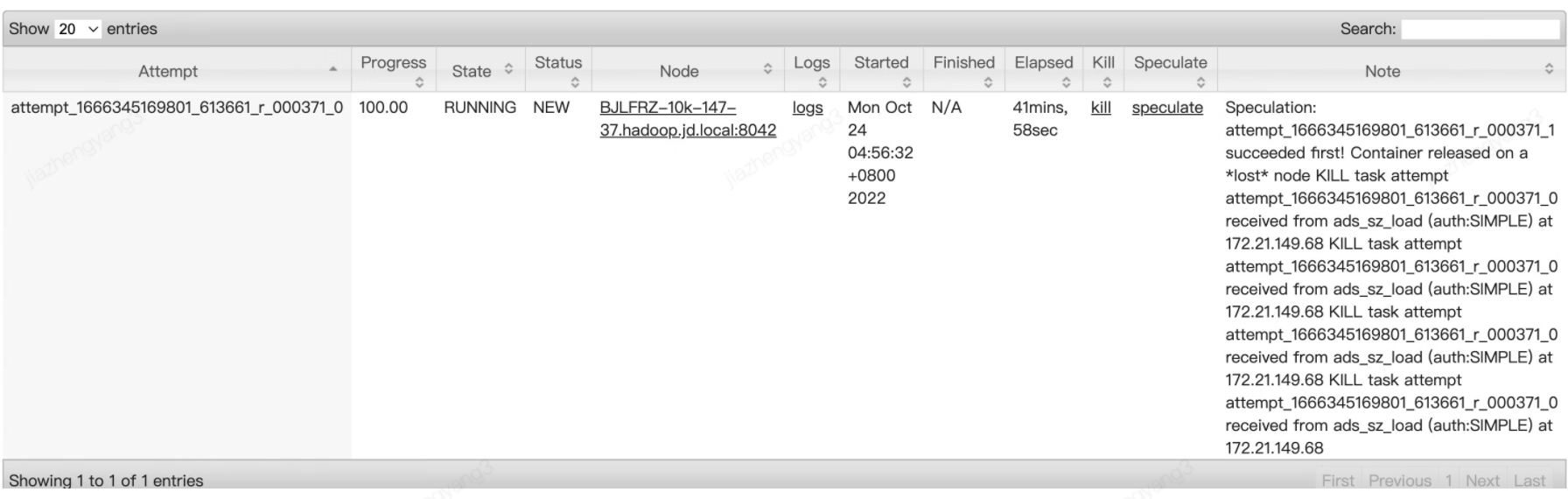
3.3 原因排查
观察上述监控界面,发现卡住的两个TA是运行在同一个节点上的,于是怀疑是节点问题,查看节点监控发现确实是节点除了问题,如下图所示。具体出了什么问题,这个就交给运维同学去排查了。