数据开发之离线计算_Spark运行架构
1.Spark核心组件
1.1 物理节点:
ClusterManager
ClusterManager是指集群上用于分配资源的资源调度器,一个spark集群中只有一台ClusterManager节点。当spark引擎搭建在原生的资源管理集群standalone上时,由standalone集群的Master节点来担任;当spark引擎搭建在yarn集群上时,由yarn中的resourcemanager节点来担任。
Worker
worker是集群当中运行计算代码的节点,在standalone集群中通过slave文件配置的worker节点来担任,在yarn集群中由nodemanager节点来担任。
1.2 应用程序
Application
spark application是指用户编写的spark应用程序,其中包含了driver功能的代码和运行在多个worker工作节点上的executer代码。
Driver
driver就是application中运行main()函数并创建SparkContext的代码部分,由driver为spark应用程序准备运行环境,并负责与ClusterManager通讯进行资源申请与任务调度、监控,并在executer都运行完毕之后将SparkContext关闭。根据spark在不同集群上的不同运行模式,driver代码可以运行在standalone集群上的本地client端,也可以运行在standalone集群上的Master节点上,也可以运行在yarn集群上的本地client端,也可以在yarn集群上作为ApplicationMaster启动,具体运行形式见下述1.3节。
Executer
executer就是运行在worker节点上负责运行task的计算进程。满足条件的worker会为每一个application独立的启动一个executer进程,一个worker节点可以同时为多个不同的application启动多个executer。每个executer进程都单独的运行在worker的一个JVM进程中,有一个线程池,每接收到一个task则调用一个线程来执行,所以executer中task的并行度取决于线程池的并行度。某个application的executer进程一旦被创建将一只处于运行状态,它的资源可以被多批次task复用,资源在application运行完成后才会被释放,避免重复申请资源带来的时间开销。当spark程序运行在yarn集群上时,一个executer运行在一个container容器上。
2.运行流程
2.1 流程步骤
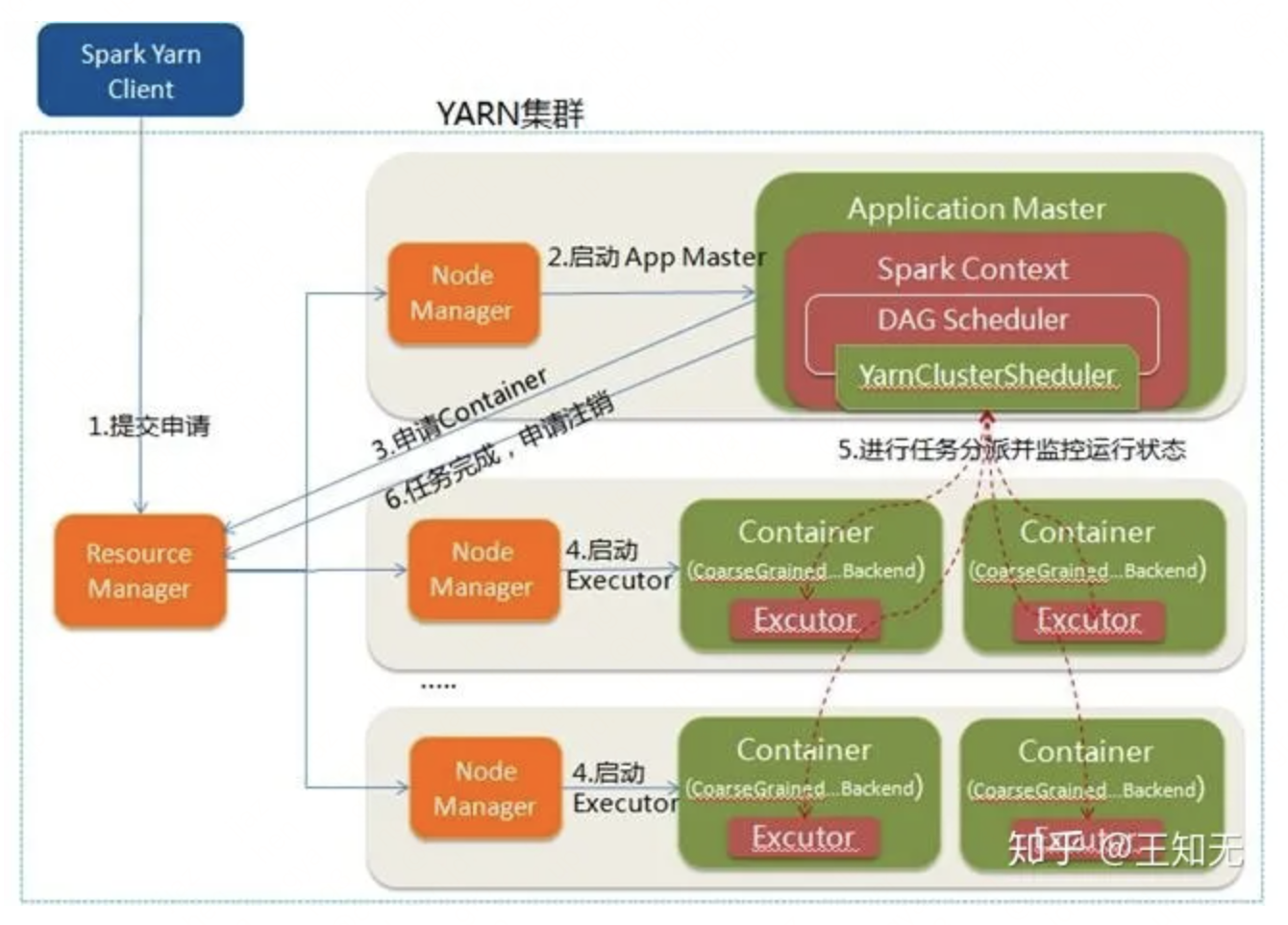
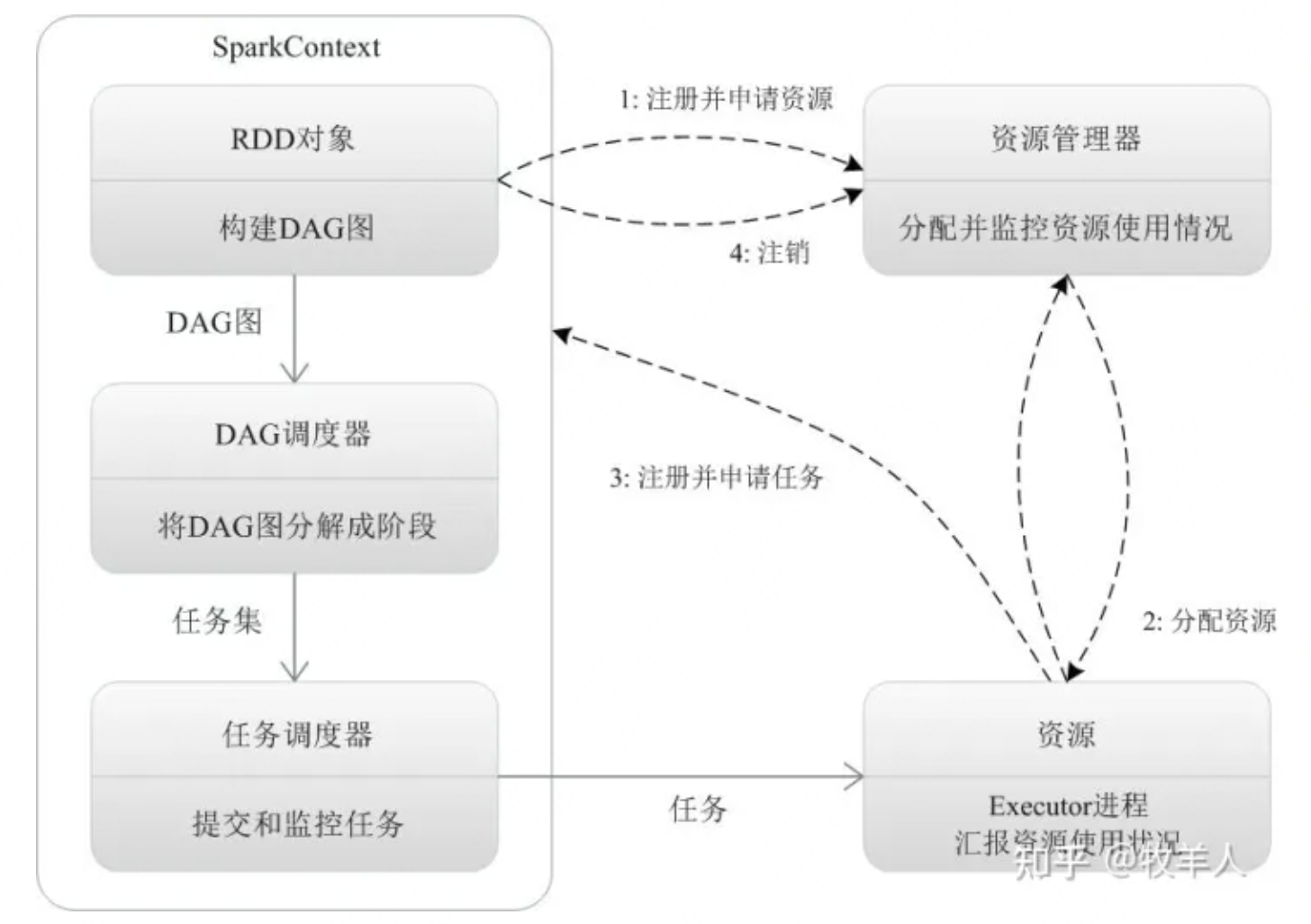
spark程序运行的基本流程图如下图:
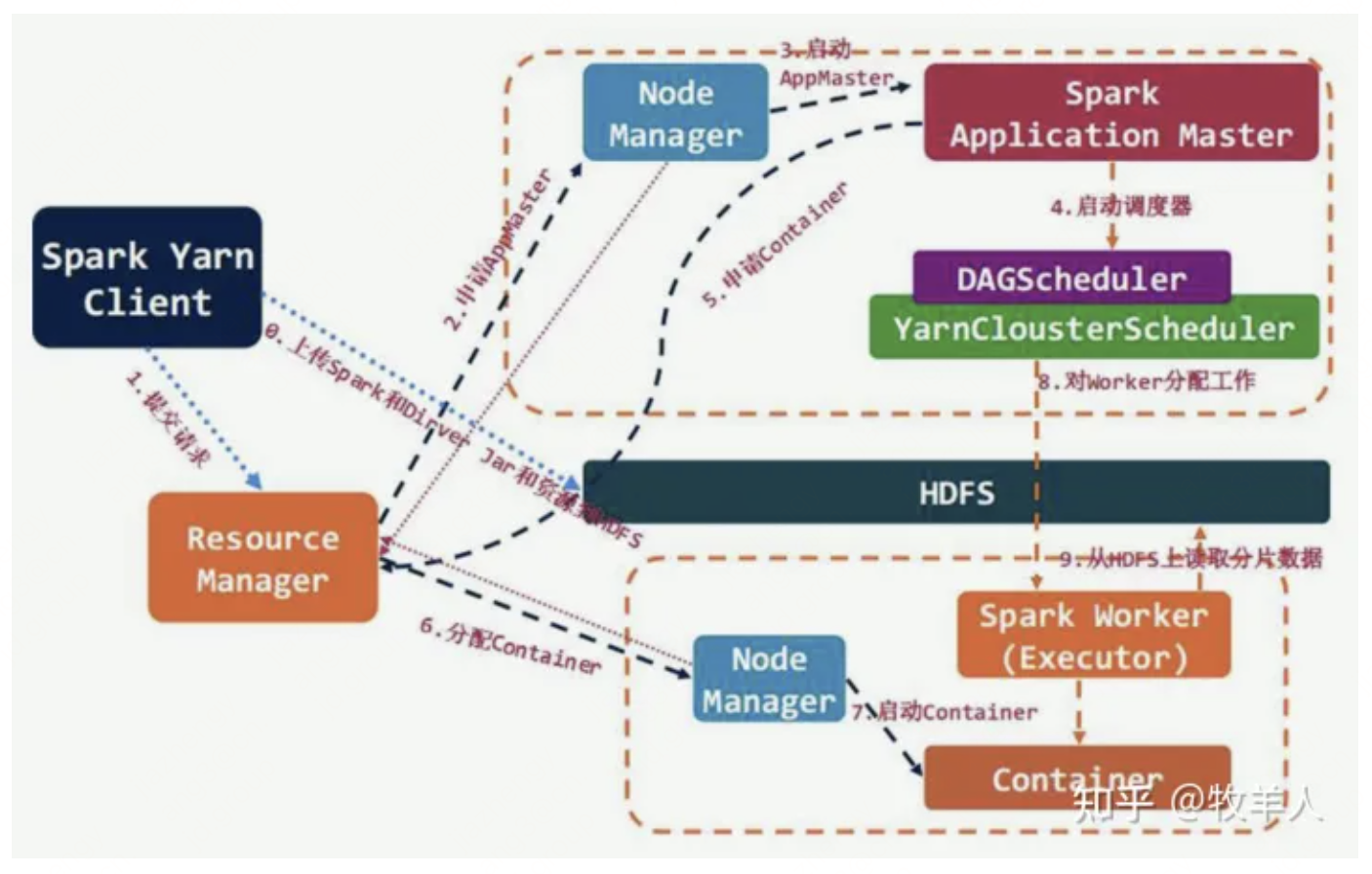
spark应用程序现在比较常用的运行模式有standalone、yarn-client、yarn-cluster三种,其中yarn-cluster模式运行流程图如下图:
spark程序运行的基本流程如下:
- 客户端提交请求,运行driver,启动SparkContext,SparkContext向ClusterManager注册并申请运行Executer的资源。
- ClusterManager分配Executer资源并启动ExecutorBackEnd,Executor的运行情况将随着心跳发送到ClusterManager。
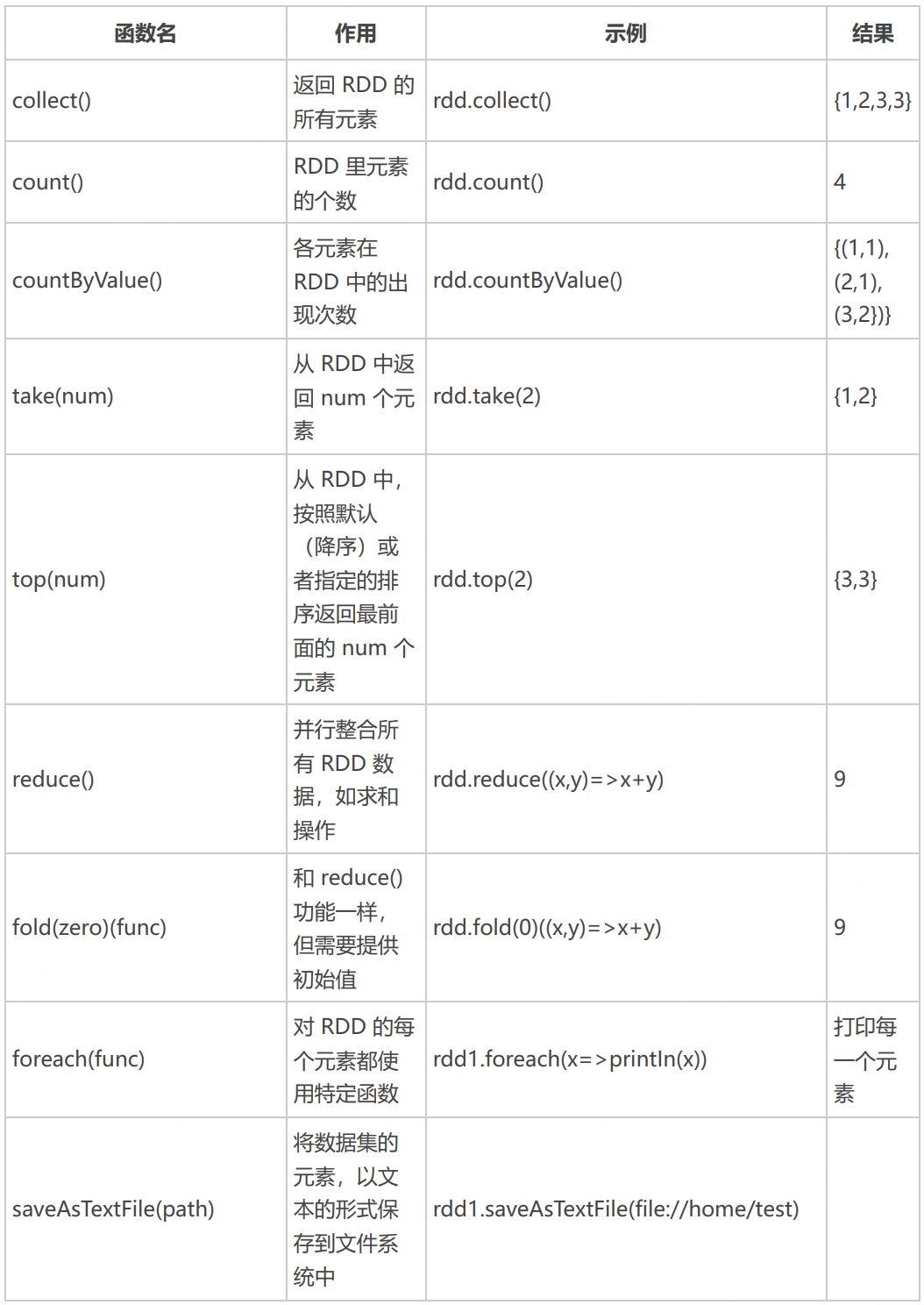
- SparkContext根据RDD行动操作(action)将application分解为不同的job,application中有多少个action就分解为多少个job,再为每一个作业按照RDD转换操作(transformation)构建一个DAG图。
- SparkContext创建DAGSchedule,对DAG进行拆分,首先将每个job按照transformation切分为最小的数据处理单元,也就是task,一个job中一般包含多个不同的RDD,每个RDD可以按照数据分区partition切分为多个task来处理,一个partition对应一个task。第二步将每个job按照transformation的宽依赖和窄依赖类型切分为顺序执行的stage,每个stage包含一个task任务集合,下一个stage必须等待上一个stage中的所有task执行完毕才可以开始执行。
- SparkContext创建TaskScheduler,将task和应用程序交给相应的executer运行。
- task在executer上运行,运行完毕释放所有资源。
2.2 转化操作与行动操作
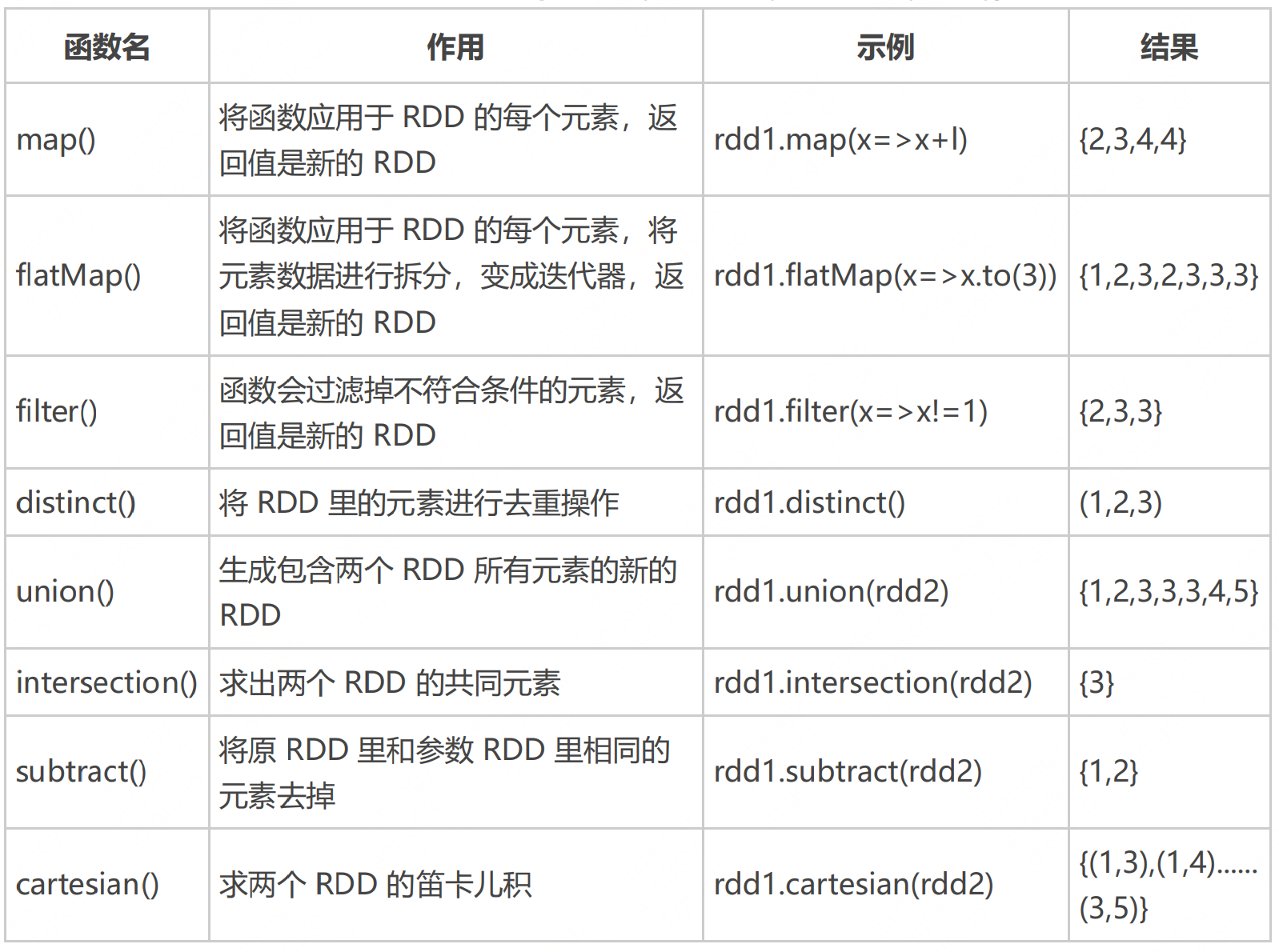
RDD就是一个分布式对象集合,本质上是保存在集群不同节点上多个数据集片段的集合,帮助统一对集群不同节点上的数据进行并行计算。对RDD的操作分为转化操作(transformation)和行动操作(action):transformation就是输入RDD输出还是RDD的操作;action就是输入RDD但是输出非RDD的操作,输入一个值或者数组等。RDD的操作都是惰性的,当RDD执行transformation时,实际计算并没有被执行,只有当RDD执行action时才会促发计算任务提交从而执行相应的计算操作。所以一个spark程序中有多少个action就决定了有多少个job。
常见transformation如下:
常见action如下:
2.3 宽依赖与窄依赖
RDD之间有依赖关系:父RDD的一个partition只输出给一个子RDD的partition,这种是窄依赖,父、子partition是一对一或者多对一的关系;父RDD的一个partition中的数据需要输出到子RDD的不同partition中去,这种是宽依赖。窄依赖与宽依赖的区别就是是否发生洗牌操作(shuffle):窄依赖是子RDD分区只依赖固定的一个或几个父RDD分区,能够独立计算得到结果;而宽依赖是指子RDD的各个分区会依赖父RDD的各个分区,这会造成父RDD中的数据在集群中重新分片,也就是shuffle操作。
spark中每一个job的DAG按照宽依赖或者说shuffle来进行拆分为必须顺序执行的stage,一个stage由多个没有shuffle关系的task组成,shuffle是spark中最耗时的操作,是决定spark任务执行速度的关键。spark基于内存计算的特性就是在shuffle write和shuffle fetch时将数据写到内存上、从内存读取,超出分配内存部分的数据就会存放到磁盘上去,所以为Stage设置合适的并行数防止过多磁盘存写也是提升spark执行速度的关键。没有shuffle关系的task的执行间隙并不会将计算完的数据写下来,而是以管道的形式传递给下一个task,一个stage执行过程是在最后进行shuffle write的时候才会将数据写下来的。stage中task的并行度是由stage的最后一个RDD的分区数来决定的,所以一般可以通过在最后reduce时添加reduceBykey(xxx,numpartiotion),join(xxx,numpartiotion)等操作来改变最后一个RDD的分区数,从而提高stage的并行度。
DAGSchedule不仅负责job的分割,还负责管理调度stage的提交,DAGSchedule会为每一个stage分配一个stageID,用来表示stage的优先级,stageID越小优先级越高,越应该先提交给集群运行。stage的提交需要参考stage之间的依赖关系和父stage的执行情况,一个stage必须等待它的所有父stage执行完毕才能被提交。
3 不同集群运行模式
3.1 Spark on Standalone
Standalone模式是Spark实现的资源调度框架,其主要的节点有本地Client节点、Master节点和Worker节点。其中Driver既可以运行在Master节点上中,也可以运行在本地Client端。当用spark-shell交互式工具提交Spark任务时,Driver在Master节点上运行;当使用spark-submit工具提交Job或者在Eclipse、IDEA等开发平台上使用new SparkConf().setMaster(“spark://master:7077”)方式运行Spark任务时,Driver是运行在本地Client端上的。
3.2 Spark on Yarn-Client
Yarn-Client模式中,Driver在本地Client中运行,这种模式使得Spark application可以和客户端进行交互,因为Driver在客户端,所以可以通过webUI访问Driver查看任务执行状态。在Yarn-Client模式,yarn启动的Application Master的作用仅仅是调度资源,为executor申请container,运行在Client节点上的Driver会与这些container保持通行来调度他们工作,也就是说Client不能离开。
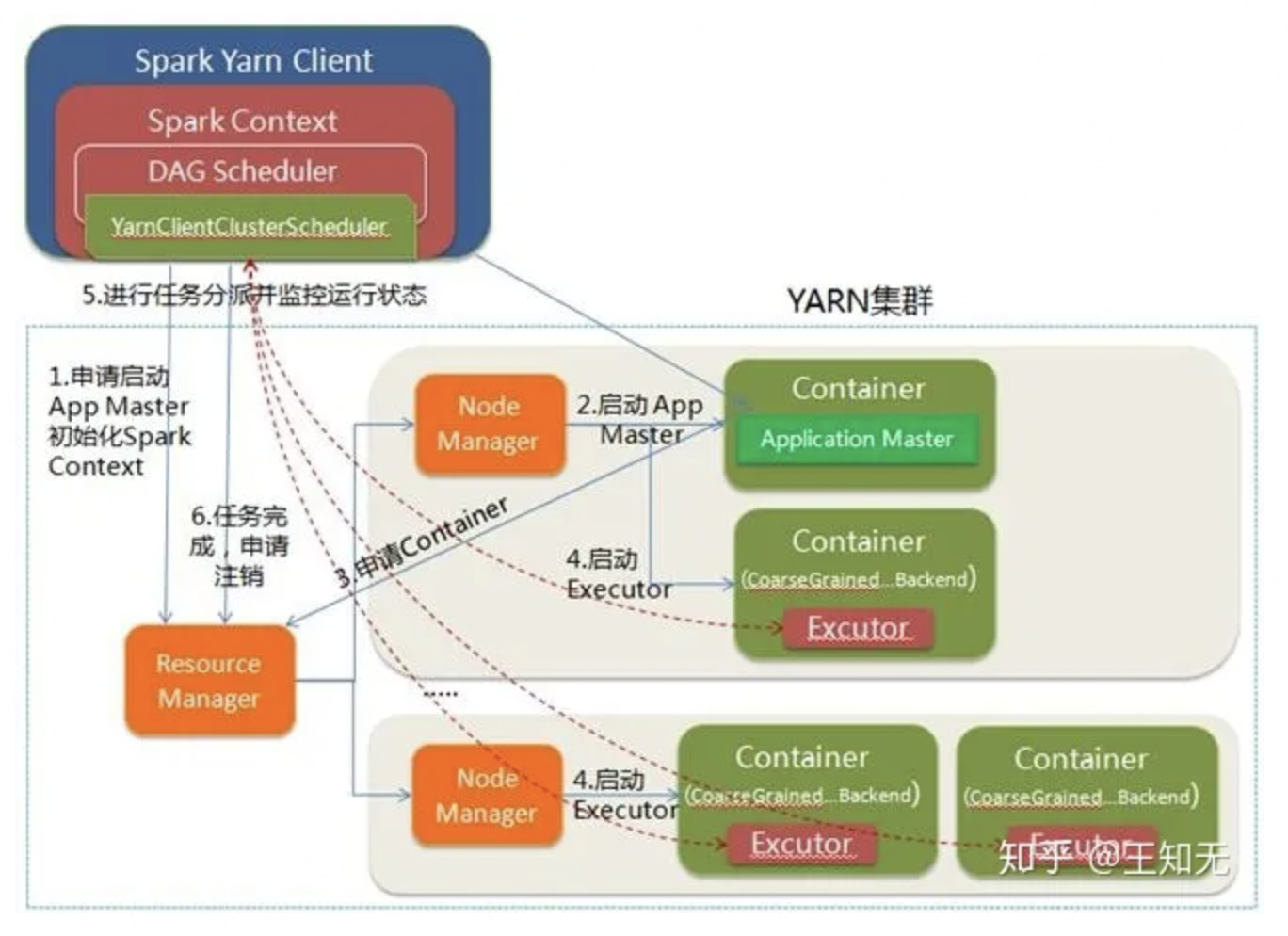
3.3 Spark on Yarn-Cluster
Yarn-Cluster模式中,当用户向Yarn中提交一个Spark应用程序后,在Yarn为该程序分配的第一个container中启动Application Master,同时还运行Driver代码进行SparkContext等运行环境的初始化。在Yarn-Cluster模式,yarn启动的Application Master不仅负责调度资源,还要运行Driver。用户提交了应用程序之后,就可以关掉client,应用程序会继续在yarn上运行。