数据开发之离线计算_HiveSQL执行计划与JobHistory日志
1.HiveSQL执行计划与Stage划分
1.1 Hive划分Stage原理
hive的逻辑计划生成器会将sql计算语句抽象成算子,然后物理计划生成器会将hivesql按照join、groupby、orderby等有shuffle操作的算子或者filter、where条件进行划分划分为不同的stage。
一个stage可能是一个mapreduce任务;也可能是一个抽数阶段;也可能是一个合并阶段;也可能是一个limit阶段;也可能是一个不会执行的空stage,比如filter、where等运算经过优化器后会放在其他stage里执行。这些stage组成一个有向无环图,必须按照顺序从上游往下执行,默认情况下hive一次只会执行一个stage,如果开启了并发执行也可以同时执行几个没有依赖关系的stage。
1.2 Explain执行计划
使用explain命令可以清晰的看到一个hivesql查询命令的执行计划,包括了stage划分与每个stage之间的依赖关系。这个执行计划对于我们了解底层原理、hive调优、排查数据倾斜有很大的帮助。
拿如下查询hivesql作为例子:
1 | explain |
得到如下执行计划:
1 | STAGE DEPENDENCIES: |
从最外层开始看,首先是STAGE DEPENDENCIES表示划分得到的各个stage之间的依赖关系,从中可以看出各个satge的执行顺序。
第二部分是STAGE PLANS表示各个stage的执行计划,详细介绍其中每个参数的含义:
Map Reduce表示这是一个mapreduce类型的stage,其中Map Operator Tree表示map端的执行计划树,Reduce Operator Tree表示reduce端的执行计划树。TableScan表示表扫描操作,map端的第一个操作肯定都是加载表,其中alias属性表示表名称,Statistics属性表示表统计信息,包含表中数据条数,数据大小等。Filter Operator表示过滤操作,其中predicate属性表示过滤条件,Statistics属性表示表统计信息。Select Operator表示选取操作,其中expressions属性表示选取的字段名称和字段类型,outputColumnNames属性表示选取的列名称,Statistics属性表示表统计信息。Group By Operator表示分组聚合操作,其中aggregations属性表示聚合函数信息,mode属性表示聚合模式,该属性的hash表示随机聚合,partial表示局部聚合,final表示最终聚合,keys属性表示分组字段,如果没有分组就没有该属性,outputColumnNames属性表示聚合后输出的列名,Statistics属性表示表统计信息,包含分组聚合之后的数据条数、数据大小等。Reduce Output Operator表示输出到redece端操作,其中sort order属性表示规则,属性值为空表示不排序,+表示正序排序,-表示倒序排序,+-表示先按第一列正序再按第二列倒序。Map Join Operator表示join操作,其中condition map属性表示join方式,keys属性表示join字段,outputColumnNames属性比哦哈斯join完输出的列名,Statistics属性表示join完之后生成的数据条数、数据大小等。File Output Operator表示文件输出操作,compressed属性表示是否压缩,table属性表示表的信息,包括输入输出文件格式化方式、序列化方式等。Fetch Operator表示客户端获取数据操作,limit属性表示限制的获取条数,属性值为-1表示不限制条数。
1.3 定位HiveSQL中产生数据倾斜的代码段
数据倾斜一般是大key问题导致的,主要通过hadoop监控平台来查看相关指标判断到底是不是大key导致的。可以通过如下两种方法判断:
通过reduce执行时间elapsed time来判断,如果某个reduce的所有推测任务都明显比其他reduce任务执行时间长,那就是大key问题。
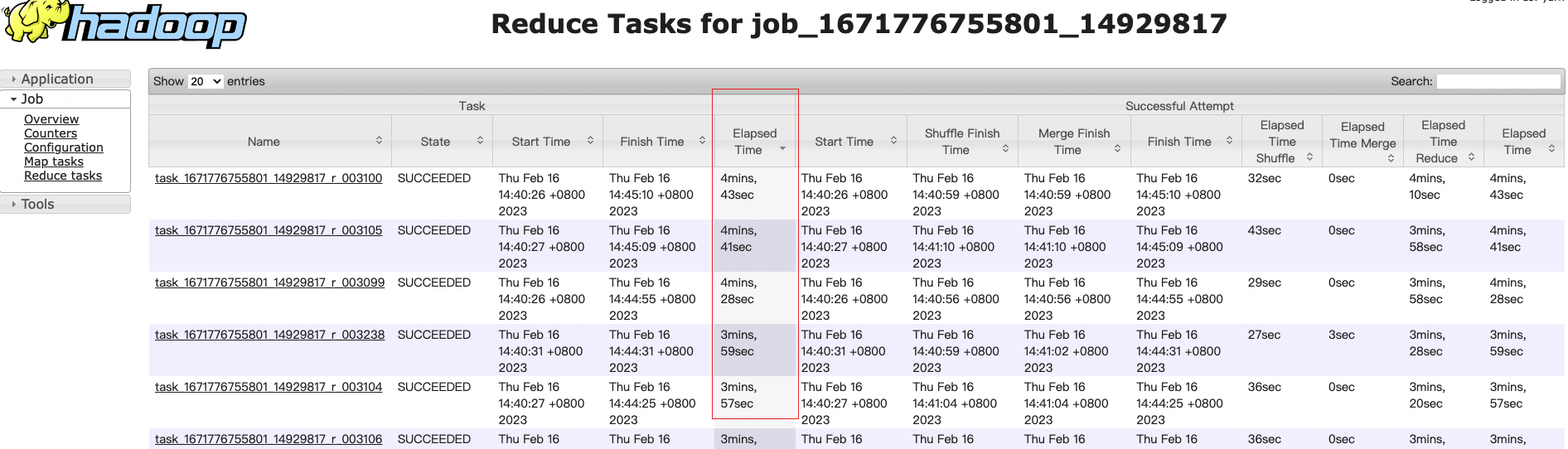
进入task的监控界面点击查看每个task的counters信息,通过比较输入数据大小number of bytes read也可以进行判断,如果某个reduce任务明显比其他reduce任务输入数据量大,那就是大key问题。
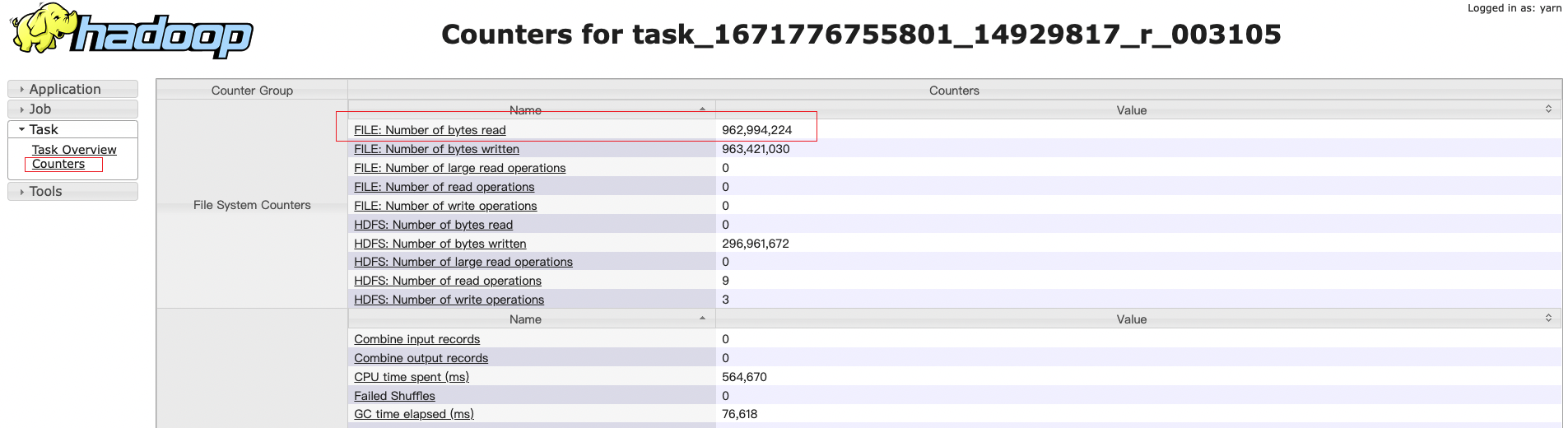


确定是大key问题之后可以通过执行日志可以根据发生倾斜的mapreduce任务的jobname确定对应的stageID,然后查看该hivesql的执行计划,就可以确定该stageID对应的是哪一段代码,从而对该段代码进行优化。
2.MapReduce日志搜集原理
2.1 MapReduce日志类型
在Hadoop2.0中,每个mapreduce的job的日志包含两部分,job日志和task日志。job日志是由ApplicationMaster产生的,详细记录了job启动时间、运行时间、每个任务的启动时间、运行时间、counter值等信息。task日志是由container产生的,主要是task在container的JVM中运行产生的日志,主要包括stderr、stdout、syslog三个文件,如下图所示。

2.2 Job日志生产流程
第一步:提交作业,ApplicationMaster启动和运行过程中,将日志默认写到/tmp/hadoop-yarn/staging/yarn/.staging/job_XXXXX_XXX/目录下,该目录下主要包括.jhist、.summary、.xml三个文件,分别表示job运行日志、job概要信息、job配置属性。其中job概要信息只有如下一句话:
1 | jobId=job_1385051297072_0002,submitTime=1385393834983,launchTime=1385393974505,firstMapTaskLaunchTime=1385393976706,firstReduceTaskLaunchTime=1385393982581,finishTime=1385393985417,resourcesPerMap=1024,resourcesPerReduce=1024,numMaps=8,numReduces=1,user=yarn,queue=default,status=SUCCEEDED,mapSlotSeconds=47,reduceSlotSeconds=5,jobName=QuasiMonteCarlo |
第二步:所有task运行完成之后,AM将上述三个文件默认拷贝到/tmp/hadoop-yarn/staging/history/done_intermediate/${username}目录下,拷贝过程中在这三个新文件名后添加_tmp,拷贝完成后再去掉_tmp。
第三步:**周期性扫描线程将done_intermediate文件夹中的日志文件默认转移到/tmp/hadoop-yarn/staging/history/done目录下,同时删除.summary文件,因为.jhist文件已经涵盖了该文件的所有内容。
第四步:AM移除/tmp/hadoop-yarn/staging/yarn/.staging/job_XXXXX_XXX/目录并结束运行。
2.3 Task日志生产流程
默认情况下,task日志是由每个container产生的,每个MR任务的AM本身也是运行在container上的,且是编号为000001的container,可以将它看成一个特殊的task,也会产生自己的task日志。也就是说一个AM会分别产生job日志和task日志两份独立的日志。默认情况下,task日志只会存放在container所在nodemanager的本地磁盘上,默认放在该节点的logs/userlogs目录下。
但是将task日志存放在各个节点上不便于统一管理和分析,需要通过配置参数mapred.job.history.server.embedded=true来启用日志聚合功能。开启该功能后,各个task运行完成后会将stderr、stdout、syslog三个日志文件合并成一个文件推送到hdfs的一个目录下。
2.4 JobHistoryServer服务
JobHistoryServer是hadoop集群一个独立的服务,为了减轻RM的负担通常部署在一台独立的机器上,需要在mapred-site.xml文件中进行特殊配置并使用sbin/mr-jobhistory-daemon.sh start jobhistoryserver命令启动该服务。
JobHistoryServer的主要工作是完成job日志的迁移,分析和展示job中的各种启动时间、结束时间、运行时间、counter等数据,并生成指向job日志和task日志的连接。

在MR任务运行中,点击任务日志中的如上链接就可以进入yarn监控界面。如果没有部署JobHistoryServer那么在MR任务运行结束之后点击该链接就无法进入任何监控界面,也无法通过java代码获取该任务的counter信息;如果部署了JobHistoryServer那么在MR任务运行结束之后点击该链接就会自动跳转到jobhistory监控界面,如下图所示,也可以通过java代码获取到该任务的counter信息。

3.MapReduce默认Counter含义与使用
3.1 默认Counter含义
hadoop的yarn监控平台和jobhistory监控平台都为用户提供了counter监控窗口用于观察mapreduce job运行期间的各种细节数据,在对mapreduce任务进行性能调优工作时通常也是基于这些counter的数值表现来评估是否优化。

counter有group的概念,用于表示逻辑上相同范围的所有数值。
FileSystemCounters
mapreduce job运行时需要与本地磁盘、hdfs等不同的文件系统进行数据IO,这个group用于表示job与这些文件系统的IO统计。
FILE_BYTES_READ表示job读取本地文件系统的总字节数。如果map的输入数据都来自hdfs系统,那么map阶段的该counter数值应该是0。但是reduce的输入数据都是从map输出文件中拉取经过shuffle和merge后存储在reduce节点本地磁盘中的,所以无论如何reduce阶段该counter数值就是reduce的输入数据总字节数。FILE_BYTES_WRITTEN表示job写到本地文件系统的总字节数。了解了mapreduce运行流程之后就知道,map在运行过程中会将从环形内存缓冲区溢出的数据spill到本地磁盘中,并在map计算结束时将多个小spill文件合并成大的spill文件,如下图中的步骤9,所以map阶段的该counter数值就是map task往本地磁盘中溢出写的数据总字节数。reduce端在shuffle时会不断根据key从map生成的spill文件中拉取对应分区数据,再做merge并spill写到自己的本地磁盘,如下图中的步骤13,所以reduce阶段的该counter数值就是shuffle阶段往本地本地磁盘写的数据总字节数。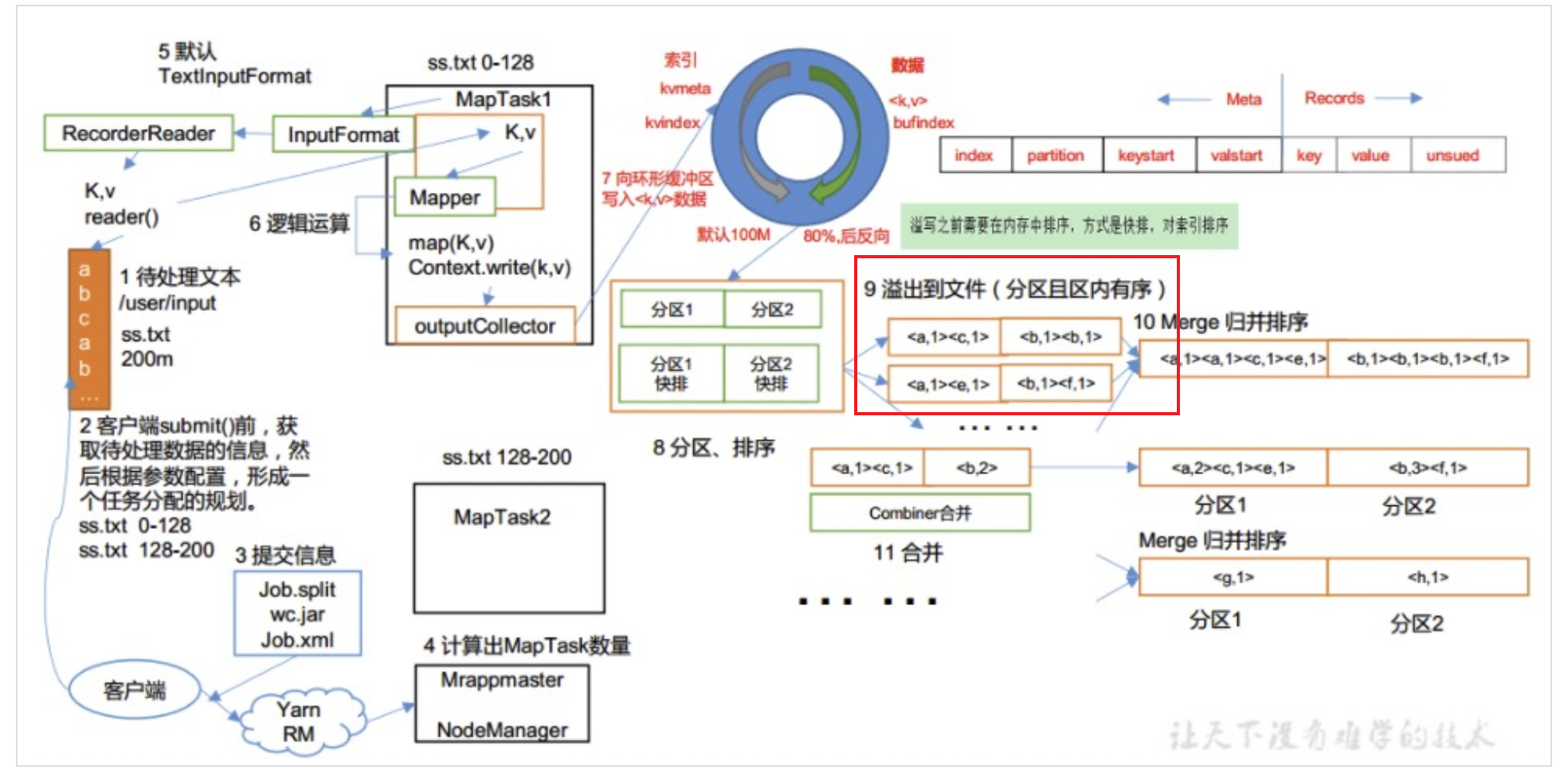
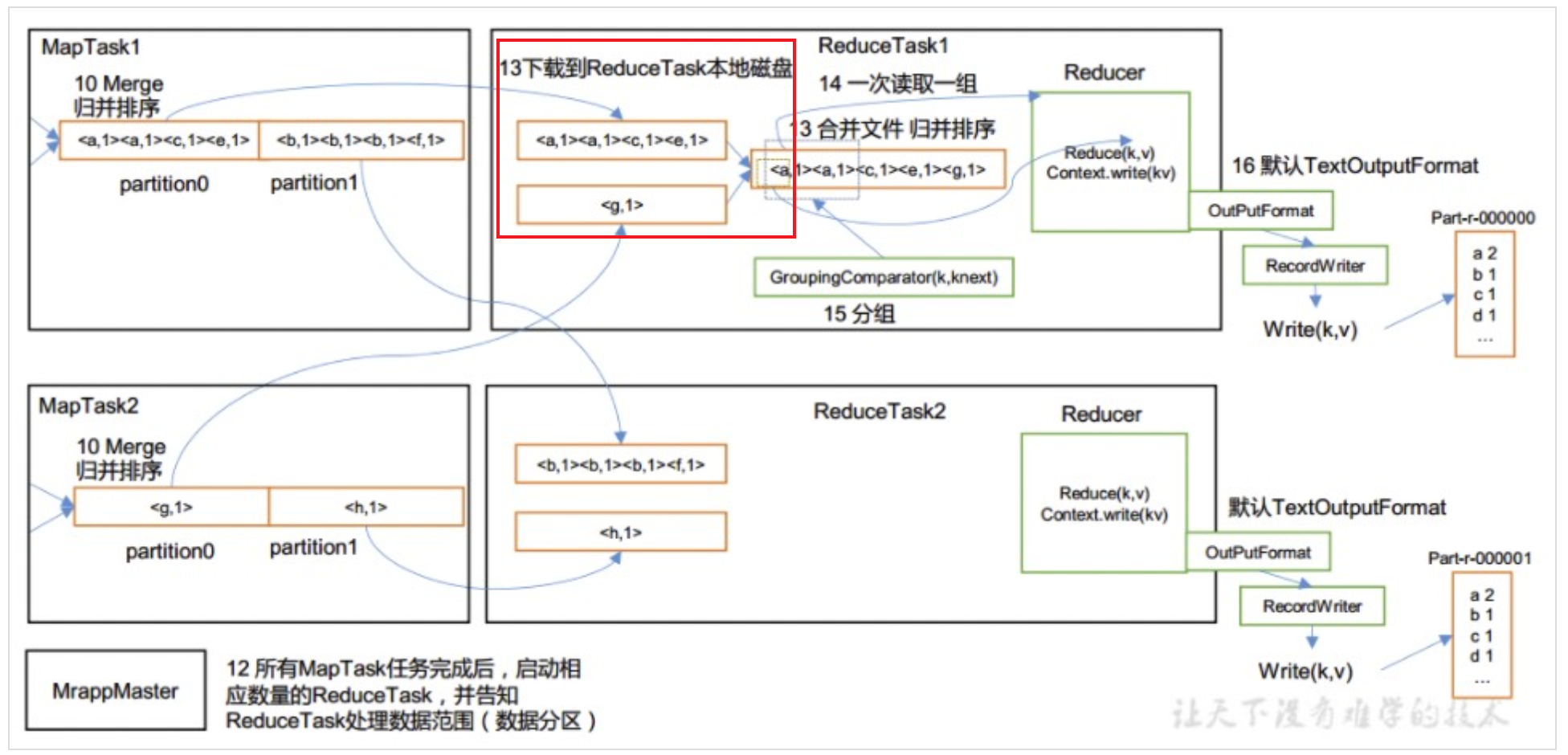
HDFS_BYTES_READ表示job从hdfs系统中读取的总字节数。只有map task运行时,才会从hdfs中读取数据,这些数据不限于源文件内容,还包括所有map的split信息元数据,所以这个counter数值会比FileInputFormatCounters.BYTES_READ数值要略大一些。HDFS_BYTES_WRITTEN表示job写入hdfs系统中的总字节数。reduce task的计算结果最终都会写入hdfs系统,也就是一个job执行结果的总数据量。


ShuffleErrors
该group用于表述shuffle过程中各种错误情况的发生次数,基本就是reduce端的copy线程从map端的spill文件中抓取分区数据时的各种错误。
BAD_ID每个map task的TA都会有一个id,如attempt_201109020150_0254_m_000000_0,如果reduce端的copy线程抓取过来的元数据中的TA id不是这种标准格式,那么此counter数值+1。CONNECTION表示reduce端的copy线程建立到map端的连接有误数量。IO_ERROR表示reduce端的copy线程在抓取map端数据时出现IOException的数量。WRONG_LENGTHmap端存储的spill中间文件是经过压缩的有格式数据,所以它有两个length信息,原数据长度和压缩后数据长度,如果这两个length信息传输有误,那么此counter值增加。WRONG_MAP每个copy线程都是有明确目的的,为某个reduce端抓取某个map端数据,如果抓取的map端不是之前定义好的map端,则此counter值增加。WRONG_reduce与上一个counter类似,copy线程抓取的数据不是为之前定义好的reduce端准备的,则此cunter值增加。
JobCounters
该group与job调度有关。
Map-ReduceFramework
该group包含了很多的job执行细节数据。
Combine input recordscombine是mapreduce计算过程中的一个可选步骤,在maptask阶段的最后可以选择进行一轮combine操作,如上图中的步骤11,本质就是为每个map task的输出文件现在本地进行一次局部的reduce,用于降低shuffle过程中的网络传输数据大小。该counter表示job的combine阶段的数据输入条数,与map的输出条数是一致的。Combine output recordscombiner按照相同key进行聚合之后,在map端就自己解决了很多重复数据,该counter表示combine阶段的数据输出条数,也表示最终在map端spill中间文件中的数据总条数。Failed Shuffles表示copy线程在抓取map端数据过程中,因为网络链接异常或是IO异常导致的shuffle错误次数。GC time elapsed(ms)表示所有执行map task和reduce task的JVM总共的GC时间消耗。Map input records表示map阶段从hdfs系统读取的数据总行数。Map output records表示map阶段直接输出的数据总行数,就是map方法中调用context.write的次数,也是未经过Combine时的原生输出条数。Map output bytesmap方法的输出结果都会以kv的形式序列化到环形内存缓冲区中,这里的bytes值序列化后的最终字节之和。Merged Map outputs表示在shuffle过程中总共经历了多少次merge动作。如果未开启combine操作那么map阶段的merge次数肯定是0。Reduce input groups此处的group表示经过按相同key进行merge聚合之后的一条数据,该counter表示reduce阶段读取的总group数量。Reduce input records表示reduce端从map端spill文件获取的总数据条数,如果开启了combine该数值就等于Combine output records数值,如果没开启就等于Map output records数值。Reduce output records表示reduce执行后输出的数据总条数。Reduce shuffle bytes表示reduce端的copy线程总共从map端抓取的中间数据总字节数。Shuffled Maps一个reduce端从一个map端拉取中间数据,则该counter+1。如果所有reduce都读取了所有map端,那么该counter的总数等于reduce number * map number。Spilled Recordsspill过程在map端和reduce端都会发生,该counter统计了这两个阶段从内存往磁盘中spill的数据总条数。SPLIT_RAW_BYTES与map端的split相关元数据都会存储在hdfs系统中,该counter表示这部分额外信息的字节大小。
FileInputFormatCounters
BYTES_READ表示所有map task或者reduce task的所有输入数据的总字节数。
3.2 自定义Counter
在MR程序开发过程中,除了默认的counter信息之外,还需要我们通过自定义的counter对分布式计算过程进行监控,获取一些特定的运行状态信息。以java程序开发为例,通常需要以下三个步骤:
第一步:在map类或reduce类中创建一个自己的counter枚举类,类名和枚举值名没有特定规范。
1 | public static enum FileRecorder{ |
第二步:在map()或reduce()方法中需要进行统计的地方进行数值变更。
1 | public void map(NullWritable key, OrcStruct value, Context context){ |
第三步:在job运行完成之后获取对应统计信息,用于打印或者校验等。
1 | long sourceCount = job.getCounters().findCounter(BulkLoadMapper.FileRecorder.SrcRecorder).getValue(); |
在MR应用程序自定义了counter之后,该MR程序运行的yarn监控平台和jobhistory监控平台上也会加上自定义的counter,方便用户直接查看,如下图所示。

4.Bulkload任务获取counter问题处理实例
4.1 背景
bulkload任务间歇性失败报错,查看报错日志如下,是在MR任务和load数据到hbase都完成之后报的错。
报错日志:

正常执行日志:

结合正常执行日志和报错日志可以看出,在任务运行完毕之后执行的job.getCounters()代码逻辑,是先去从代理客户端节点(也就是AM)获取counter信息,发现任务已经成功之后,重定向到jobhistoryserver去获取counter信息。那么报错发生的原因就是从jobhistoryserver中获取counter时没有找到对应job。
4.2 原因分析
拉hadoop平台侧研发人员一起分析,从报错日志中首先找非依赖jar包中我们自己写的MR程序代码,因为这种报错一般是由我们自己写的代码引起的,我们也知道自己代码的逻辑。从报错日志中,先定位到是我们自己的BulkLoadDriver类中的getCounters方法报错了。进一步分析日志,原因是任务完成->jobhistory日志归档之间是有时差的,报Unknown Job的原因是获取任务counter时,任务已经完成,但是JH还没完成归档,导致的JH没有对应job信息。
上文中我们提到过job日志要经过两次迁移,先从yarn目录到history/done_intermediate目录,再到history/done目录。日志至少要已经完成落到history/done_intermediate目录,才可以被查询到。任务结束与日志迁移是异步进行的,当hdfs集群较为繁忙时日志迁移就会比较慢,并不会由于迁移状态没完成而影响AM的正常结束流程,平台侧也没有办法帮我们改变这个规则。
4.3 问题解决
打印自定义counter信息的这段代码的作用只是打印信息写入日志,并不影响MR任务主流程和bulkload数据流程,所以直接给这段代码加上try/catch捕捉异常代码,让该异常不影响主流程的正常结束,也算是一种降级处理。
1 | try { |