大模型_基于大模型与数据服务语义层的要素关联发现及智能生成助手
一、背景
先发优势
在交流过程中发现,很多公司在做数据治理方面就需要很大成本,只有几十张表的时候,通过数据集建模等方式去建模做数据治理,跨表查询成为难题。如果天然已经建设好了完备的语义层,直接解决了很多公司无法进入的门槛问题,而且还是极高的门槛。在这个基础之上再去做基础应用建设,甚至通用服务建设,agent模型串联应用,进度直接领先2年。
现状调研
很多chatbi应用的不足:
面向BI用户,对象受限,与权限强耦合(可以转而以整体数仓用户为目标用户,让指标服务平台成为数仓新入口);
以结果数据为目标,对数据准确性要求高,幻觉零容忍(可以转而以SQL为目标,供用户修改与多轮对话);
指标范围限定在应用口径范围,覆盖面较窄;
迭代较慢,无法实时更新语义层知识库。
项目目标
引擎类型概念一定会被弱化,存储介质概念一定会被弱化,随着湖仓等引擎技术发展,通过doris等计算引擎直接读同一份存储的模式一定会逐步取代ck,统一语义层的建设势在必行,上层LLM应用建设会更加通用便捷。(数据治理发展趋势不可阻挡)
指标、维度、维值、修饰关联推荐,这个能力非常好用。
根据语义模型实时更新字典和向量库。
目标是替代冗余etl、报表取数开发,实现从bdp到指标服务的引流,推动逻辑数仓建设。
未来展望
能力方向:生成sql&数据、数据总结陈述、记忆多轮交互、推理数据归因
落地实现:
1.当前数据开发工程师的很多工作,包括数据采集,etl开发,数据建模,数据治理,应用报表产出,其实都非常有意义,也非常值得做深入,这些工作的好坏甚至能主导一个企业的经营决策。但是当前繁杂或者临时的业务取数工作往往会耗费数据开发工程师大量精力。data agent和chat bi当前在取代这部分取数工程师的工作上还是非常有前景的,主要替代临时取数和报表工作。
2.大模型的主攻和长处是aigc类的发散性思维;给出准确性结论或者准确性数据是小模型的擅长之处,大模型在做此类工作时反而容易出错,所以大小模型的协同是很重要的一个方向,让专业的模型做擅长的事。比如大模型不太会处理小数点数,让它比较9.11和9.8很大概率出错,那么如果我们转而让它画一个折线图或者柱状图,我们反而也能很直观看出比较结果,结果也会比较准确。
3.除了data agent,未来在大数据领域还应该有ask agent,因为大数据是有海量数据的,往往使用者自己也不知道要怎么用数据是有价值的,他问不出问题来。那么应该有一个ask agent能够提出有价值的问题,然后data agent再来回答。这个ask我目前想到的,可以基于异常检查、行业经验、人工注入打标等,这个方向也确实值得探索。
二、核心技术
1.现有技术背景
随着指标服务的持续运行,在指标实际的生产和管理过程中,由于业务发展阶段的不同、团队任务、业务素养和数据思维的差异,各个业务团队在进行指标查询和指标注册过程中,很难识别到已有指标已经实现的目标逻辑,也很难感知现有度量字段已经支持了哪些指标逻辑,导致业务团队宁愿重新注册数据表、指标、维度等元信息。这就导致各业务方自有的指标越来越多,同义不同名、指标重复建设、二义性等问题越来越多,指标可信度也越来越低,维护和管理成本越来越高。
传统的指标服务数据查询通常需要用户具备一定的SQL和数据库知识基础,对于非技术背景的业务运营用户来说,学习和掌握SQL会是一个挑战,由于不熟悉相关语法和命令,也不了解如何将业务需求转化为有效的查询语句,导致数据分析门槛较高、数据查询效率低下。
鉴于上述指标服务的指标检索和数据查询现状,有必要针对元信息冗余和数据查询门槛高等问题进行优化,因此设计一种基于指标服务的要素关联检索和智能生成的方法及装置,显得十分迫切和重要。
2.技术目标
本方案提供一种基于指标服务的要素关联检索和智能生成的方法,该方法包括:
- 将构建指标体系的指标服务业务元信息初始化加载到词典、缓存和向量数据库中,并进行周期调度更新;
- 对输入文本进行检索,计算检索结果与输入文本的相似度并进行排序;
- 基于检索结果构建请求大模型的提示信息,包括背景知识、回答规则、请求案例;
- 使用输入文本结合提示信息请求大模型,得到非结构化的智能生成文本;
- 将大模型返回的非结构化内容按照特殊标识符进行切分和结构化处理,并对结构化请求结果进行格式和业务属性纠正。
通过指标服务元信息知识库,能够帮助用户快速检索定位指标、维度、数据表,避免重复创建;利用已有指标、维度、物理表信息作为知识和经验帮助大模型为用户生成物理表建表语句和数据查询语句,帮助用户提高指标服务平台使用和数据查询效率。
3.核心流程
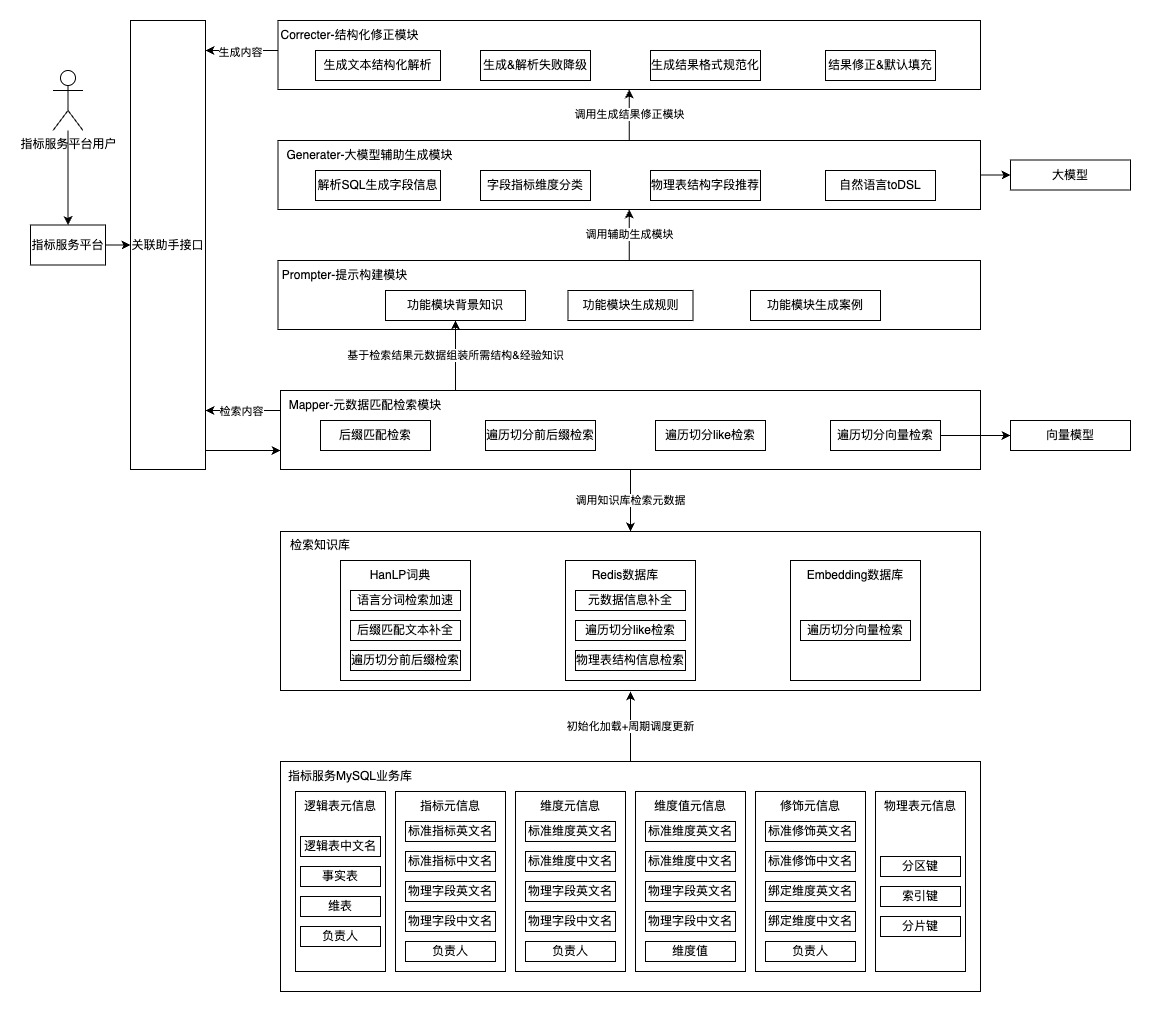
本实施方案提供了一套基于指标服务的要素关联检索和智能生成的方法及装置,如上图所示,包括本地知识库加载模块、元信息关联检索模块、提示构建模块、大模型智能生成模块、结果修正模块。
进一步地,所述本地知识库加载模块读取指标服务平台MySQL业务数据库中的逻辑表、指标、维度、维度值、修饰、物理表元信息,其中包括逻辑表的中文名、表类型、负责人,指标的标准中文名、标准英文名、物理字段中文名、物理字段英文名、负责人,维度的标准中文名、标准英文名、物理字段中文名、物理字段英文名、负责人,维度值的标准维度中文名、标准维度英文名、物理字段中文名、物理字段英文名、负责人,修饰的标准中文名、标准英文名、绑定维度中文名、绑定维度英文名、负责人,物理表的分区字段、索引字段、分片字段等信息。
进一步地,所述本地知识库实时更新,包括:定期对比指标服务平台MySQL业务数据库中数据表、指标、维度、维度值与本地知识库中的元信息,如果有变化,则重新读取MySQL业务数据库数据,并加载到本地知识库;通过消息队列监听指标服务平台的数据表、指标、维度、维度值元数据变更事件,根据消息队列信息更新本地知识库中的元信息。
进一步地,将所述指标服务平台元信息存储到BinTrie结构实现的HanLP词典中,对于逻辑表、指标、维度、维度值、修饰和物理表分别使用中文名或英文名构建词典树节点,另外直接使用维度值构成词典树节点,使用逻辑表、指标、维度、维度值、修饰和物理表的表类型、表结构字段、度量字段、聚合类型、负责人等属性作为词典树节点值。
进一步地,将所述指标服务平台元信息存储到Redis数据库中,对于逻辑表、指标、维度、维度值、修饰和物理表分别使用中文名或英文名作为Key,使用逻辑表、指标、维度、维度值、修饰和物理表的表类型、表结构字段、度量字段、聚合类型、负责人等属性作为Value。
进一步地,将所述指标服务平台元信息存储到PGVector向量数据库中,调用本地部署的Dmeta-Embedding-zh向量模型将逻辑表、指标、维度、维度值、修饰和物理表的中文名或英文名转化为向量数组,并将逻辑表、指标、维度、维度值、修饰和物理表的表类型、表结构字段、度量字段、聚合类型、负责人等属性作为向量元信息存储到PGVector向量数据库中。
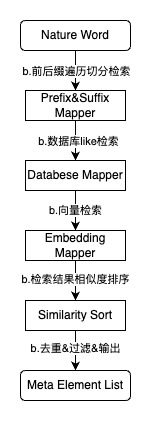
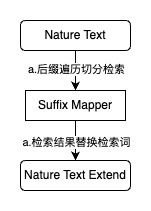
一种可能的实施方案中,提供了输入文本补全能力,如上图所示,对输入文本按照指定单元长度和步长进行后缀遍历切分,得到后缀文本数组,然后依次使用所述HanLP词典检索数组中的后缀文本,得到对应的检索结果;计算所有检索结果与原始输入文本之前的相似度,所述计算方法为先计算出两个字符串之间由一个转化成另一个所需要的最少编辑次数,编辑类型包括增、删、改,然后将最少编辑次数除以两个字符串中最长字符串的长度,得到与原始输入文本相似度最高的检索结果,作为文本补全结果返回给用户。
一种可能的实施方案中,提供了元信息关联检索能力,如上图所示,对输入文本按照指定单元长度和步长进行前缀和后缀遍历切分,得到检索文本数组,然后分别使用所述HanLP词典、Redis数据库、PGVector向量数据库依次对每个检索文本检索,包括:使用所述HanLP词典进行前缀匹配和后缀匹配查询,得到具有相同前缀或后缀的指标服务元信息;使用所述Redis数据库进行精确匹配查询,得到完全匹配的指标服务元信息;调用本地部署的开源向量模型Dmeta-Embedding-zh将检索文本转化为向量数组,使用所述向量数据库对该向量数组进行语义查询,得到语义相似的指标服务元信息。计算上述三种检索方式得到的所有检索结果与原始输入文本之间的相似度,对检索结果按文本相似度进行排序和过滤,将文本相似度最高的几个指标服务元信息返回给用户,作为指标服务元信息备选项。
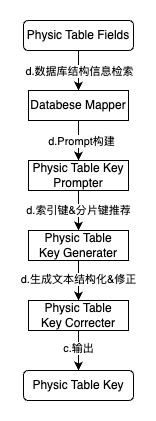
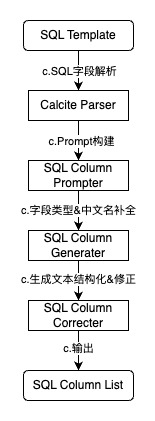
一种可能的实施方案中,提供了查询SQL语句字段解析和智能生成能力,如上图所示,包括:使用Calcite对查询SQL进行解析,得到Select子句中的所有物理字段英文名,作为原始信息;定义物理字段补全信息输出规则,需要根据物理字段英文名补全物理字段中文名、物理字段数据类型、物理字段描述信息;定义查询SQL物理字段信息生产案例,包括一个常见查询SQL和预期生成的物理字段补全信息列表;结合上述所有提示信息请求本地部署的开源大模型Qwen2.5-7B得到物理字段补全信息文本;将大模型返回的文本按规则定义好的JSON标识符号进行切分,并结构化解析为物理字段信息列表,返回给用户。
一种可能的实施方案中,提供了建表SQL语句的索引字段、分片字段智能推荐能力,如上图所示,包括:对输入的建表字段使用所述Redis数据库进行检索,查询这些字段在已存在表中分别作为索引字段和分片字段的次数,将查询结果作为背景知识;定义建表语句的索引字段、分片字段输出规则,索引字段需要按从低基维度到高基维度排序,分片字段只能有一个;定义索引字段、分片字段推荐案例,包括一些常见维度字段列表和预期推荐的常用索引字段、分片字段;结合上述所有提示信息请求本地部署的开源大模型Qwen2.5-7B得到推荐的建表索引字段和分片字段;将大模型返回的文本按规则定义好的JSON标识符号进行切分,并结构化解析为索引字段列表和分片字段,返回给用户。
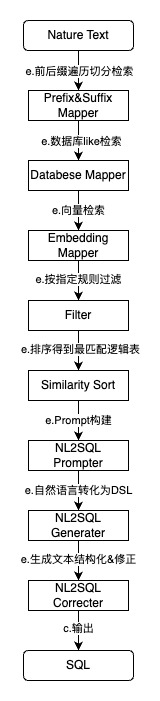
一种可能的实施案例中,提供了将数据查询自然语言转化为SQL的能力,如上图所示,包括:对输入文本按照指定单元长度和步长进行前缀和后缀遍历切分,得到检索文本数组;使用所述HanLP词典进行前缀匹配和后缀匹配查询,得到具有相同前缀或后缀的指标服务元信息;使用所述Redis数据库进行精确匹配查询,得到完全匹配的指标服务元信息;调用本地部署的开源向量模型Dmeta-Embedding-zh将检索文本转化为向量数组,使用所述向量数据库进行语义查询,得到语义相似的指标服务元信息;计算所有检索结果与原始输入文本之间的相似度,对检索结果按文本相似度进行排序和过滤;以逻辑表为检索结果基本单元,每个匹配到的逻辑表、指标、维度、维度值检索结果元信息分别把文本相似度作为分数加到对应逻辑表上,最后得到得分最高的逻辑表作为本次查询的数据表;定义数据查询SQL输出规则,必须包含时间过滤条件和时间粒度过滤条件;定义数据查询自然语言转化为SQL案例,包括一个常见数据查询自然语言文本和预期生成的数据查询SQL;结合上述所有提示信息请求本地部署的开源大模型Qwen2.5-7B得到数据查询SQL语句;将大模型返回数据查询SQL语句使用Calcite进行格式校验,校验失败则进行重试或按照失败原因给用户返校验成功则请求数据库执行数据查询SQL,并将数据查询结果返回给用户。
三、过程启发
- LLM大模型真正的价值体现在使用场景的发掘,使用场景发掘的越多、越适配,价值就越高。大模型本身对于广大用户来说除了百度百科对话机器人并没有多大价值,如多少多少B,评分多高,对于用户来说意义不大,如上述指标编辑模块中借助大模型进行指标别名智能填充的使用场景,就是一个非常好的使用case,借助大模型给了用户预期外的惊喜。
- 物理字段、创建人其实应该是很关键的得分属性,比如根据某人名下自己创建的指标/维度。
- 根据物理字段关联搜索已经存在的物理字段和标准指标/维度的绑定关系,具有一定使用价值。
- 自己多去用,多去指标服务平台的指标、维度、修饰、逻辑表页面多去点点。这个项目的最关键的就是存储元数据结构的定义和filter的属性定义,前者决定根据关键字能关联查询到哪些信息,后者觉得在特点场景下要把那些关联查询到的信息展现给用户看。
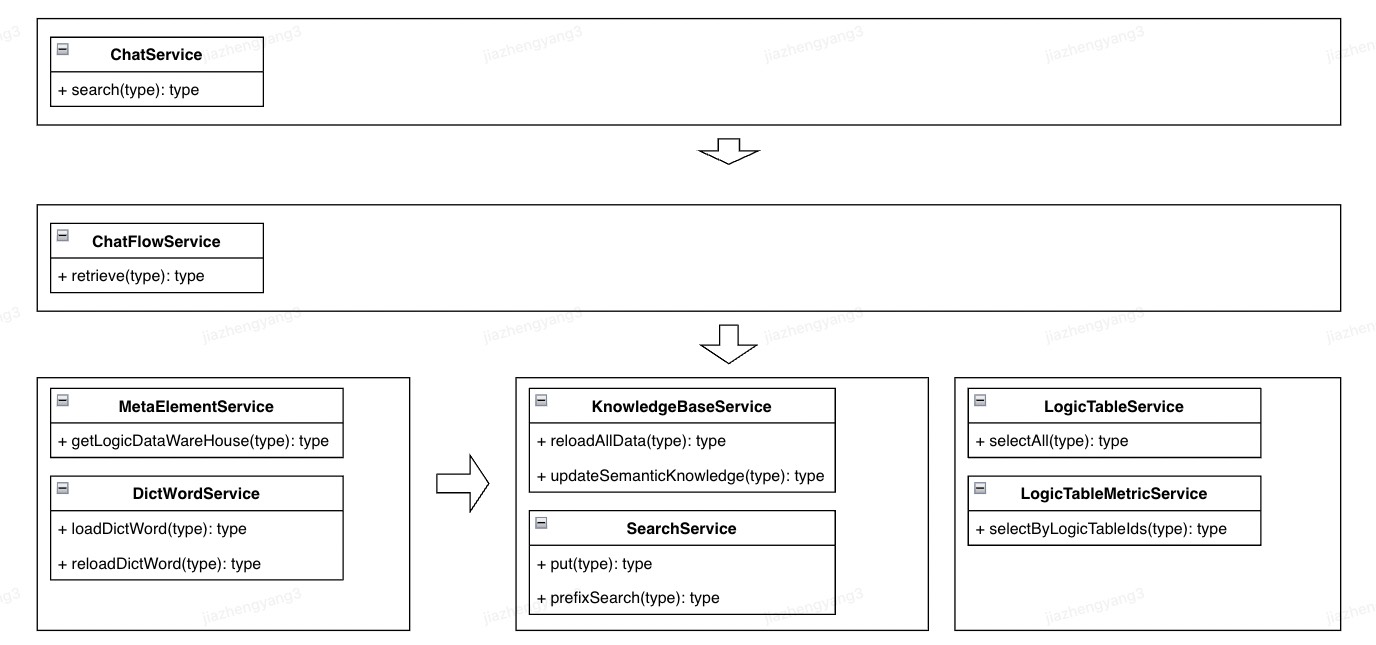
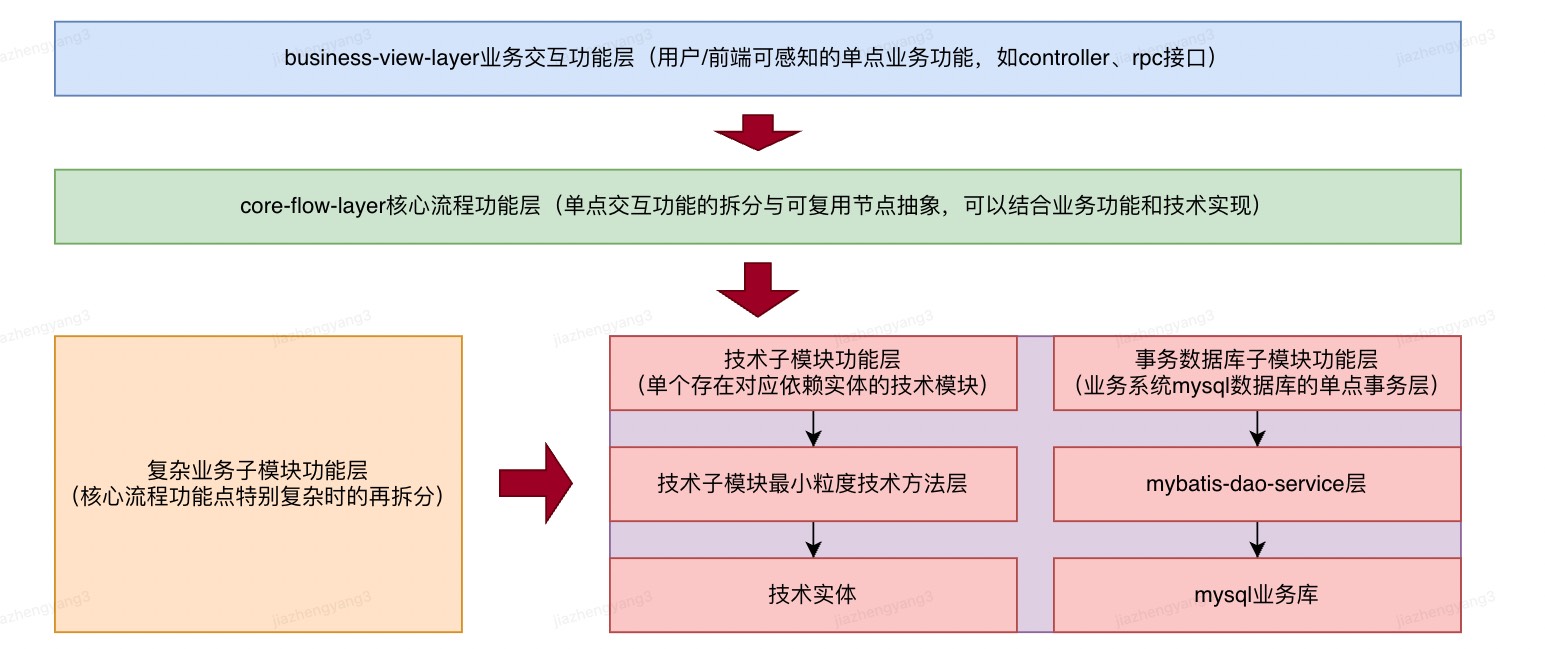
四、代码架构
service服务层层级架构,这套架构是我自己根据SuperSonic项目总结,并在自己项目中应用起来的。非常清晰实用,这也是读开源项目的一大收获。
其中技术子模块功能层的技术实体包括向量库、向量引擎、LLM模型、本地词典等各种各样的技术组件。
基于上述分层我自己项目中代码中的接口架构: